web
火眼辩魑魅

进去说shell学姐,显然访问tgshell。
直接打phpinfo();发现命令可以执行,但是继续执行发现禁了很多,但是发现反引号没禁。


|
|

直面天命
提示有个路由,看描述不出意外是爆破路由,用bp爆太慢了,直接ai写个代码爆,得到aazz
|
|
然后源码提示有参数,直接用arjun爆破得到filename

解法一:ssti
然后直接读源码app.py
|
|
看源码发现直面天命替换成了{{}}。然后查看一下secret_key。嗯没错了

打直面2*2天命,回显

接下来就是打ssti,编码绕过了
|
|
解法二:目录穿越

直面天命(复仇)
访问aazz,直接得到源码
|
|
|
|
这个调出来不容易,原型是
|
|
然后16进制编码即可,相当好用,如果小括号,cycler没禁用基本可用
|
|
贴一个类似payload,虽然这里不能用
|
|
AAA偷渡阴平(无字母数字rce)
|
|
解法一:get_defined_vars()
|
|

解法二:getallheaders()

这个没知道获取的请求头位置,即爆破位置,所以要不断发包,下面有2种指定位置的打法,但是没复现出
ByteCTF一道题的分析与学习PHP无参数函数的利用-先知社区
解法三:session_id()
|
|
|
|

本来还有解法,但是没复现出来,可以参考下面的文章
无参数RCE绕过的详细总结(六种方法)_无参数的取反rce-CSDN博客
AAA偷渡阴平(复仇)
|
|
打上面法3

非预期
|
|

前端GAME
打vite文件读取漏洞(CVE-2025-30208)
【CVE-2025-30208】| Vite-漏洞分析与复现-CSDN博客
Vite存在CVE-2025-30208安全漏洞(附修复方案和演示示例) _ 潘子夜个人博客
先试试读环境:http://127.0.0.1:58549/@fs/etc/passwd?import&raw??
|
|

接下来找flag路径

所以最后打
|
|
前端GAME Plus
flag路径还是在原地方

根据上面的思路搜索vite文件读取漏洞,找到一篇好文
Vite开发服务器任意文件读取漏洞分析复现(CVE-2025-31125)-先知社区
经过尝试,发现是CVE-2025-31486
|
|
也参考此文复现与修复指南:Vite任意文件读取漏洞bypass(CVE-2025-31486)
|
|
解码得flag

前端GAME Ultra
考最新的cve
复现与修复指南:Vite再次bypass(CVE-2025-32395)
打/@fs/tmp/可以看到绝对路径

原型poc是
|
|
|
|

也可以用代码实现
|
|
|
|
具体详细请看上面所分享文章
找最新cve还得看阿里云漏洞库
(ez)upload
扫描没找到源码,但是看到index.php.bak,可以联想到uploads.php.bak源码就在其中

|
|
|
|
而且这里一定要进行name传参,因为代码有basename($_FILES[’name’][’name’]);
这里有2种解法
第一种:打一句话木马

这里/.是为了绕过pathinfo,防止其获取文件后缀,至于为什么要a/../具体参考
从0CTF一道题看move_uploaded_file的一个细节问题-安全KER - 安全资讯平台
打进了木马之后就不多说。

这里的php文件是在uploads的文件目录下
|
|
这里本来是没有1.php的,所以可以直接打1.php/.


如果传../1.php/.,这样的话1.php就是传在与网页根目录下(即与uploads文件夹同一目录)
这种解法还有一种变形就是.user.ini配合图片马,这里就不需要/.绕过pathinfo



|
|
浅析.htaccess和.user.ini文件上传 - FreeBuf网络安全行业门户具体看此文
第二种:脏数据绕过
利用大量无用数据使正则失效(如果不限制大小的话,是个很好的通解)


什么文件上传?
访问class.php有
|
|
这个链子很显然啊
|
|
最后exp是
|
|

什么文件上传?(复仇)
依旧看class.php
|
|
上面的方法打不了,看到file_exists结合文件上传那就是打phar反序列化了
刚好春秋杯我也做了,打这个需要配环境,这里不多讲,直接分享文章
|
|
但是文件上传设置了后缀,提示是3个小写字母,gpt写一个爆破后缀的代码(一开始也爆不出,将bp抓包的数据给他然后再爆就行)
|
|
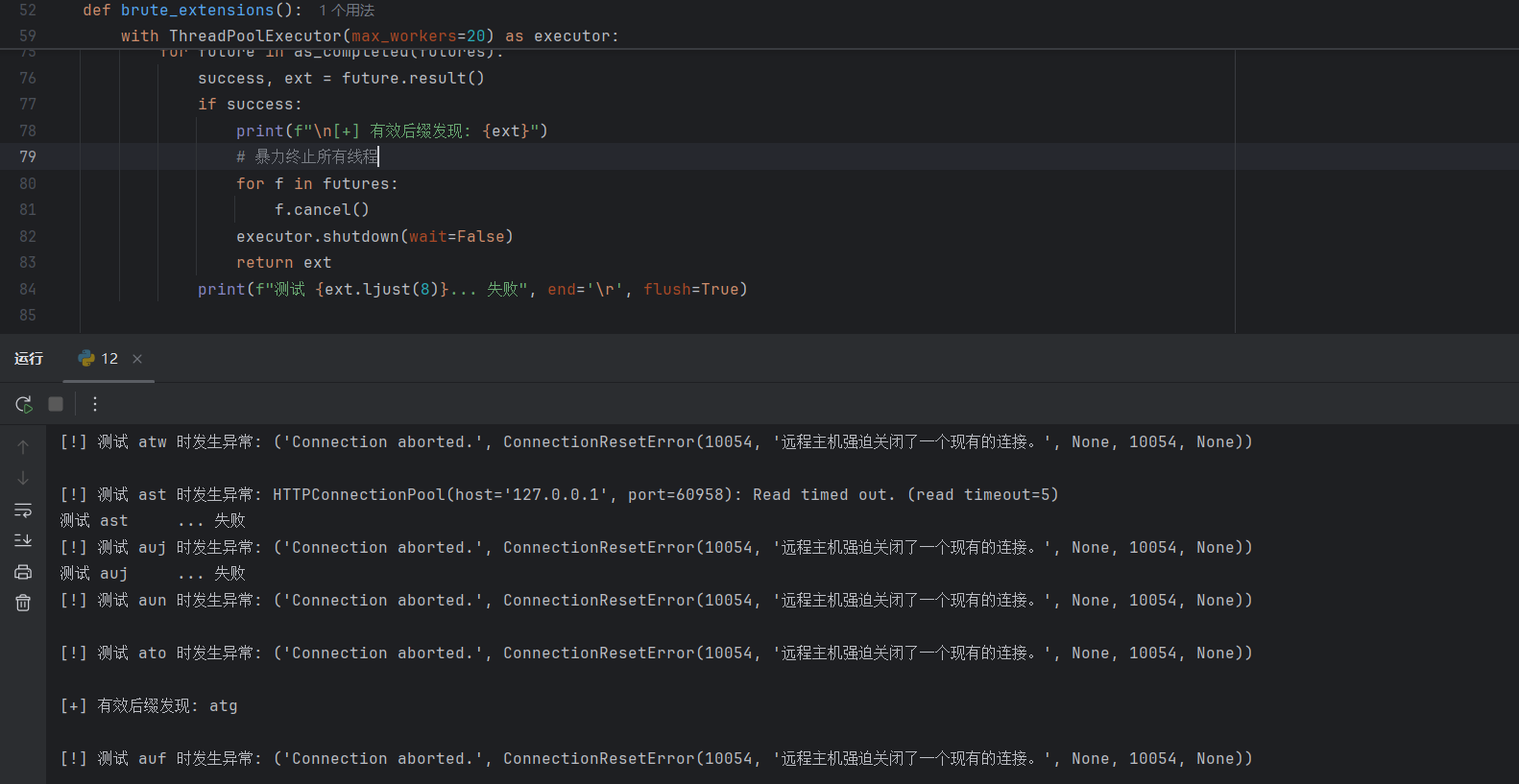
接下来就是将生成的phar文件改后缀为atg,然后上传,然后get传参触发phar
|
|
再post执行命令就好

老登,炸鱼来了?
|
|
漏洞点是
|
|
第一次输入一个任意的 name ,使得 safe 被赋值为 nil ,然后立刻读取flag,此时err 还会是 nil
|
|
熟悉的配方,熟悉的味道
|
|
对pyramid框架无回显的学习—以一道ctf题目为例-先知社区
打pyramid内存马
|
|
|
|

但是这里其实过滤了import,但是还是能打,原因
|
|
wp是
|
|
打时间盲注
|
|
Cry
费克特尔
分解后是5个素数,ai梭了
|
|
mm不躲猫猫
将数据放在1.txt,然后提取解密就行
|
|
tRwSiAns
|
|